Problem Formulation
The first five minutes of this interview will make or break you. Before you touch architecture, you need to nail down what kind of system you're actually building, because "conversational AI" covers an enormous range of products with wildly different engineering constraints.
A customer support bot for an e-commerce company needs fast, safe, narrow responses grounded in product documentation. A general-purpose assistant like ChatGPT needs broad world knowledge, multi-turn coherence, and the ability to handle almost any topic. A domain-specific copilot (think: a coding assistant or a medical triage bot) needs deep vertical knowledge, tight safety constraints, and often regulatory compliance. Don't let the interviewer assume you know which one you're building. Ask.
Interview tip: Open with: "Before I design anything, can I clarify the product scope? I'm thinking about whether this is a narrow-domain support bot, a general assistant, or something in between, since that changes almost every decision downstream." This signals systems thinking before you've drawn a single box.
Clarifying the ML Objective
ML framing: Given a conversation history and optional retrieved context, the model generates the next assistant turn as a sequence of tokens, conditioned on a system prompt and user intent.
The business goal is to resolve user queries accurately and efficiently. The ML task is autoregressive language generation, but that's actually a container for several sub-problems. Intent classification decides what the user wants. A retrieval model fetches grounding context. A router decides whether to call a tool or generate directly. The LLM itself handles generation. You're not designing one model; you're designing an orchestrated pipeline where each component has its own ML objective.
"Success" means different things depending on who's asking. To the product team, success is session completion rate and user satisfaction scores. To the ML team, success is response quality on held-out benchmarks, low hallucination rate, and safety eval pass rates. These don't always move together. A model that scores well on MT-Bench can still frustrate users if it's verbose, slow, or confidently wrong about your product's return policy. Make that distinction explicit with your interviewer.
Functional Requirements
Core Requirements
- Multi-turn dialogue with context retention. The model takes the full conversation history (system prompt + alternating user/assistant turns) as input and generates the next assistant response. Context window management is part of the ML problem, not just an engineering detail.
- Retrieval-augmented generation (RAG). For factual or domain-specific queries, the system retrieves relevant passages from a document corpus and injects them into the prompt. The model must learn to ground its response in retrieved context rather than rely on parametric memory.
- Tool and function calling. The model must recognize when a query requires external action (database lookup, web search, code execution) and emit a structured tool call rather than a free-text response. This is a classification sub-task embedded in the generation loop.
- Streaming token output. Responses must stream to the client token-by-token. This is a serving constraint, but it affects how you evaluate perceived latency and how you design the output pipeline.
- Safety and PII filtering. Every response passes through a safety classifier before delivery. The system must detect and suppress toxic content, policy violations, and inadvertent PII leakage in real time.
Below the line (out of scope)
- Voice-to-text and text-to-speech conversion (assume text-only interface)
- Personalized model fine-tuning per individual user
- Multi-modal inputs (images, audio, video)
Metrics
Offline metrics
Response quality is hard to capture with a single number. You'll want a few complementary signals.
Human preference win rate (the percentage of pairwise comparisons where annotators prefer your model's response over a baseline) is the gold standard, but it's expensive. Use it for major model promotions, not every experiment. For faster iteration, reward model score acts as a proxy: a trained preference model that scores responses on a 1-5 scale. It's cheap to run at scale but can overfit to annotator artifacts, so treat it as directional.
Factual grounding rate measures how often the model's response is supported by retrieved passages, scored by an NLI model or GPT-4 judge. This is your primary RAG quality signal. Hallucination rate is the inverse: the fraction of responses containing claims not supported by any retrieved or known-true source. Keep this front and center.
For safety, you need a dedicated eval suite: jailbreak success rate on a red-team benchmark, toxicity classifier pass rate, and PII leakage rate on synthetic test cases with injected personal data.
Online metrics
Session completion rate is your north star. Did the user get their answer without escalating to a human or abandoning the session? Thumbs-up/down rate gives you a direct quality signal from users, though it's sparse (most users don't rate). Task success rate (for support bots: was the issue resolved?) is the cleanest business metric but requires either human labeling or a downstream proxy like "no follow-up ticket within 24 hours."
Cost per query matters more than most ML engineers expect. At 10k concurrent sessions, the difference between a 7B and a 70B parameter model is a 10x difference in GPU spend.
Guardrail metrics
These are the metrics that can veto a model promotion even if quality looks good.
Time to first token must stay under 500ms at p99. Full response latency under 5 seconds at p99. Safety violation rate must not increase from baseline. Refusal rate (the model declining to answer legitimate queries) should stay below a defined threshold, since over-refusal is a real quality problem that often gets ignored.
Interview tip: Always distinguish offline evaluation metrics from online business metrics. Interviewers want to see you understand that a model with great AUC can still fail in production. A reward model score can look great while the model is quietly over-refusing edge cases or hallucinating product details that users never flag because they don't know they're wrong.
Constraints & Scale
For a production assistant handling 10k concurrent sessions, your numbers look roughly like this:
| Metric | Estimate |
|---|---|
| Prediction QPS | 10,000 concurrent sessions; ~2-5 generation requests/session/minute = ~500-800 RPS |
| Training data size | 1-10M curated dialogue turns for SFT; 100k-1M preference pairs for RLHF |
| Model inference latency budget | First token < 500ms (p99); full response < 5s (p99) |
| Feature freshness requirement | Query embeddings: real-time (per request); document index: hours to daily refresh |
A few constraints that will shape every design decision downstream. First, this is real-time inference, not batch. There's no tolerance for cold-start delays on the critical path. Second, the retrieval corpus may update frequently (new product docs, policy changes), so your vector index needs a refresh pipeline that doesn't require full reindexing on every update. Third, if you're serving users across different regions or demographics, fairness is a constraint: you need to monitor whether response quality degrades for non-English queries or specific user segments.
Common mistake: Candidates treat the LLM as the only model in the system and ignore the latency budget for retrieval, safety classification, and intent routing. In production, those auxiliary models often add 100-300ms to the critical path. Account for them early.
Data Preparation
Good training data is what separates a conversational AI that actually works from one that sounds plausible but fails on real users. The quality of your data pipeline determines the ceiling of your model, and interviewers at companies like OpenAI and Google know this. They'll push you here.
Data Sources
You're pulling from five distinct sources, each with different freshness, volume, and reliability characteristics.
Human-written dialogues are your gold standard. These come from professional annotators writing conversations from scratch, or from existing customer support transcripts (with user consent). Volume is typically low (tens of thousands of conversations), but quality is high. Every turn is intentional, well-formed, and follows the interaction patterns you actually want the model to learn.
Existing chat logs from production systems give you scale, but they come with baggage. Real users write sloppily, go off-topic, and sometimes say things that would get your model flagged immediately. Volume can be in the hundreds of millions of turns. Freshness is excellent since logs are near-real-time, but reliability requires heavy filtering before any of it touches your training pipeline.
Web-crawled text provides broad world knowledge for pretraining and domain adaptation. Think Common Crawl, Wikipedia, Stack Overflow, and domain-specific forums. Volume is enormous (terabytes), freshness varies by crawl cadence, and reliability is low without filtering. You're not using this for conversational fine-tuning directly; it feeds the base model or the RAG corpus.
Domain-specific documents are the backbone of your retrieval corpus. Product manuals, internal wikis, legal documents, API references. These are typically smaller in volume (thousands of documents), but extremely high value for grounding responses. Freshness matters a lot here: a stale document in your vector store is a hallucination waiting to happen.
Synthetic conversations generated via GPT-4 distillation or self-play are increasingly important for bootstrapping. You prompt a capable model to generate diverse dialogues covering edge cases your human annotation budget can't reach. Volume is controllable, freshness is on-demand, but you need to audit for quality drift and circular reasoning (the student learning bad habits from the teacher).
Key insight: For your logging schema, every conversation event should capture:session_id,turn_index,role(user/assistant/system),message_text,timestamp_ms,model_version, andclient_metadata. Locking this schema early prevents painful backfills later.
Label Generation
For a conversational AI, labels come from three places, and each has a different risk profile.
Explicit feedback is the cleanest signal. A user clicks thumbs-up or thumbs-down on a response. They rate the conversation at the end of a session. They explicitly say "that was wrong." The problem is sparsity: most users never give explicit feedback, so you're working with a biased sample of engaged (or frustrated) users.
Implicit feedback is noisier but abundant. Did the user ask a follow-up question that suggests they didn't get what they needed? Did they abandon the session mid-conversation? Did they rephrase the same question three times? These are weak labels, but at scale they're useful signals for reward model training.
Human preference labels are what you need for RLHF. Annotators see two model responses to the same prompt and pick the better one. This produces pairwise preference data that trains your reward model. The pipeline looks like this:
# Preference pair schema for RLHF data collection
{
"prompt": "conversation history up to this turn",
"response_a": "candidate response from model checkpoint A",
"response_b": "candidate response from model checkpoint B",
"preferred": "a", # annotator judgment
"annotator_id": "ann_0042",
"annotation_time_ms": 18400,
"confidence": "high" # low/medium/high
}
Label quality degrades fast if you're not careful. Annotators disagree on subjective quality. Responses that seem good in isolation look worse when you consider the full conversation context. And annotator fatigue is real: quality drops after the first hour of a session.
Warning: Label leakage is one of the most common ML system design mistakes. Always clarify the temporal boundary between features and labels. If you're training a reward model on preference pairs, the conversation history used as a feature must come entirely from before the response was generated. Any signal from after the response (user reaction, downstream behavior) is a label, not a feature.
Delayed feedback is a specific trap in conversational AI. A user might complete a task three turns after the response that actually helped them. If you naively assign credit to the most recent turn, you'll systematically mislabel good mid-conversation responses as unhelpful. Use session-level outcome labels (did the user complete their goal?) and distribute credit carefully.
Automated reward model scoring closes the gap between human annotation throughput and the volume of data you need. Once you have a trained reward model, you can score millions of responses offline and use those scores as soft labels for continued fine-tuning. Just be careful: reward model scores are proxies, and optimizing too hard against them leads to reward hacking.
Data Processing and Splits
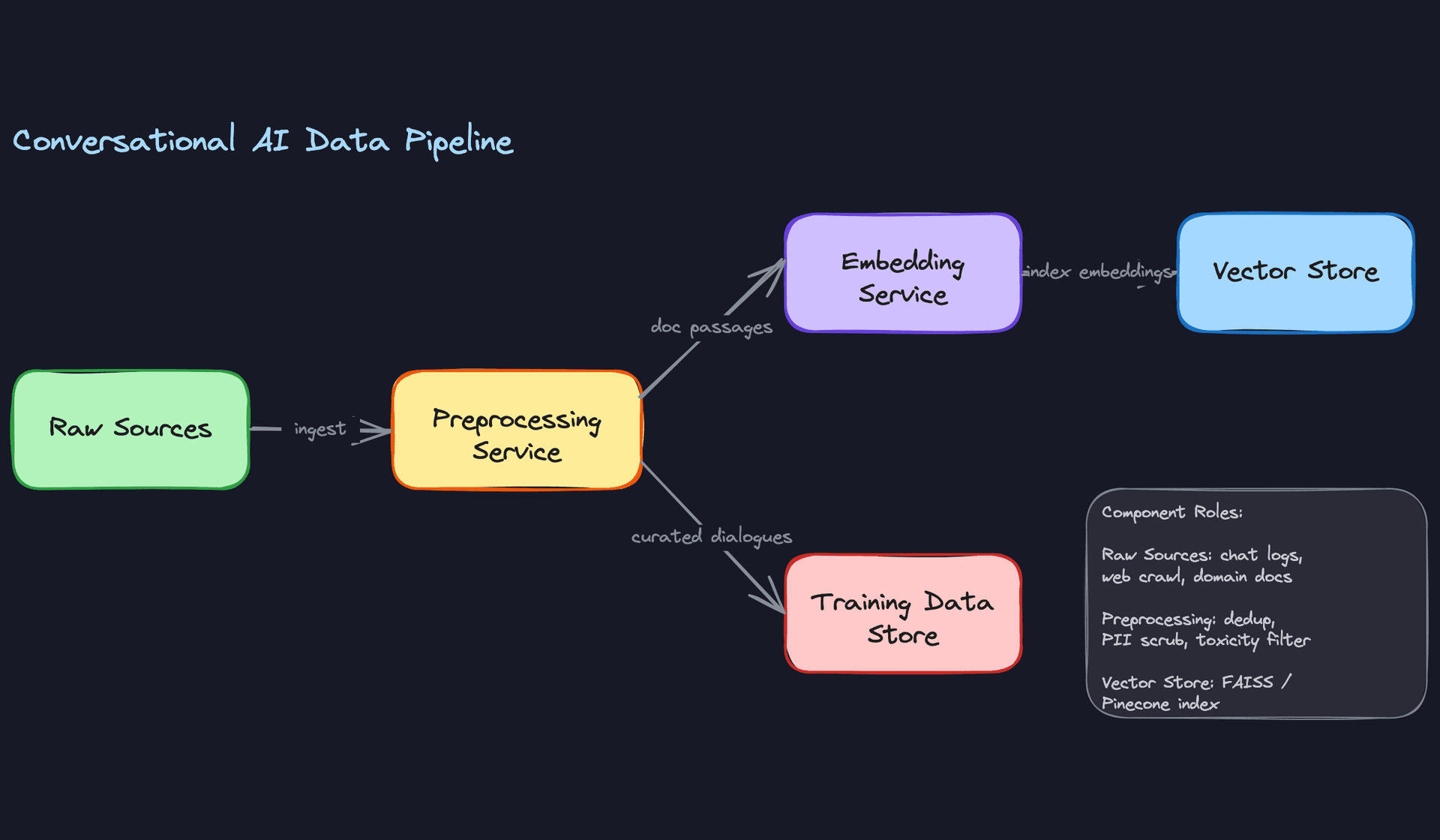
Raw data from any of these sources is not trainable. You need several passes before it's usable.
Deduplication comes first. Near-duplicate conversations inflate your training set and cause the model to overfit to specific phrasings. Use MinHash LSH for approximate deduplication at scale across millions of conversations. Exact deduplication on message text catches copy-pasted content. Run dedup across splits too: a conversation that appears in both training and validation makes your eval metrics meaningless.
PII scrubbing is non-negotiable. Names, email addresses, phone numbers, credit card numbers, and health information must be detected and removed or replaced with synthetic placeholders before any data leaves your secure processing environment. Use a combination of regex patterns and a fine-tuned NER model. Log the scrubbing rate per data source; a sudden spike usually means a new data source is leaking structured PII.
Toxicity filtering removes conversations that would teach the model harmful behaviors. Run every turn through a toxicity classifier. For training data, you typically want to filter out conversations where either the user or the assistant turn is toxic. For safety fine-tuning data, you deliberately keep some toxic user inputs paired with good refusal responses.
Language detection and segmentation matter if you're serving a multilingual system. Conversations that switch languages mid-session need special handling. Turn segmentation (splitting a raw log into clean user/assistant turn pairs) sounds trivial but breaks on edge cases: multi-message turns, system interruptions, and session boundaries that aren't cleanly delimited.
For your train/validation/test split, never split randomly. Random splits let future conversations leak into training, which inflates your offline metrics and hides real-world degradation. Always split by time.
# Time-based split for conversational data
# Training: all sessions before cutoff_date
# Validation: sessions in [cutoff_date, cutoff_date + 2 weeks]
# Test: sessions after cutoff_date + 2 weeks
TRAIN_CUTOFF = "2024-09-01"
VAL_CUTOFF = "2024-09-15"
# Test set is everything after VAL_CUTOFF
# Also split by session_id, never by turn_id
# A session should live entirely in one split
Splitting by turn rather than session is a subtle but serious mistake. If turns from the same conversation appear in both training and test, the model has seen the context and you're measuring memorization, not generalization.
Data versioning keeps your experiments reproducible. Every training run should reference an immutable snapshot of the dataset, not a live table. DVC (Data Version Control) or Delta Lake with time-travel queries both work. Tag each dataset version with the preprocessing pipeline version that produced it, the date range it covers, and the volume after each filtering stage. When a model regresses, you want to be able to diff the training data, not just the model weights.
Building the Retrieval Corpus
The RAG corpus is a separate artifact from your fine-tuning dataset, and it has its own preparation pipeline.
Start by chunking your domain documents into passages. A chunk should be semantically coherent (a paragraph or a few sentences) and fit within your retriever's input length limit. Typical chunk sizes are 256 to 512 tokens with a 64-token overlap between adjacent chunks to avoid splitting context across boundaries.
def chunk_document(text: str, chunk_size: int = 512, overlap: int = 64) -> list[str]:
tokens = tokenizer.encode(text)
chunks = []
start = 0
while start < len(tokens):
end = min(start + chunk_size, len(tokens))
chunks.append(tokenizer.decode(tokens[start:end]))
start += chunk_size - overlap
return chunks
Each chunk then gets embedded offline using a bi-encoder (a model like sentence-transformers/all-mpnet-base-v2 or a fine-tuned E5 model). These embeddings are indexed into FAISS for local deployments or Pinecone for managed infrastructure. The index is rebuilt on a schedule tied to your document update cadence. If your knowledge base changes daily, a weekly index rebuild means your retrieval is stale for up to seven days.
Common mistake: Candidates describe RAG as "embed the query, find similar documents, put them in the prompt." That's the happy path. The interviewer wants to know what happens when the retrieval quality is poor: what's your fallback, how do you detect retrieval failure, and how do you monitor mean reciprocal rank over time? Have answers for all three.
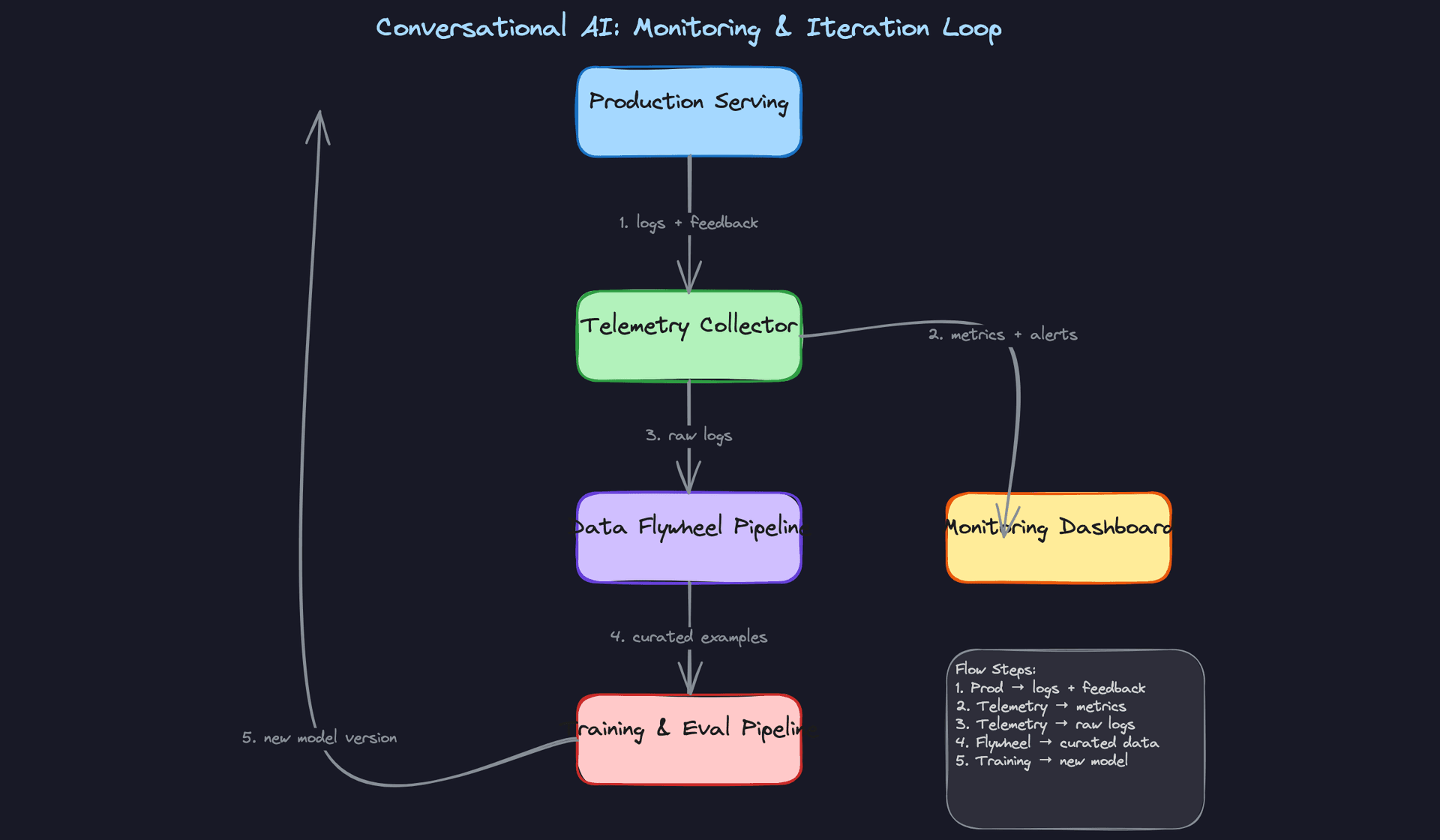
The Data Flywheel
Production traffic is your best long-term data source, but only if you close the loop deliberately.
Every response your system generates gets logged. A subset of those logs gets quality-scored by your reward model. High-scoring conversations (above a quality threshold) get flagged as candidates for the next fine-tuning round. A human review pass samples from those candidates to catch reward model errors. What passes review goes through the same dedup and PII pipeline as your original training data, then gets added to the next training dataset version.
The cadence matters. Weekly fine-tuning cycles let you respond to distribution shift within days. Monthly cycles are cheaper but mean you're always a month behind your users. The right answer depends on how fast your user population's language and intent patterns evolve, which is something you should measure explicitly via embedding drift on incoming queries.
Feature Engineering
Good feature engineering for a conversational AI system looks different from a ranking or classification problem. You're not computing click-through rates or purchase probabilities. You're assembling a prompt, and every component of that prompt is a feature. Get it wrong and the model hallucinates, ignores context, or routes to the wrong tool.
Feature Categories
Conversation Context Features
This is the most important input your model receives. The multi-turn history is tokenized with explicit role tags so the model knows who said what:
# Conversation history formatted for the LLM prompt
[
{"role": "system", "content": "You are a helpful support assistant for Acme Corp."},
{"role": "user", "content": "My order hasn't arrived yet."},
{"role": "assistant", "content": "I can help with that. What's your order number?"},
{"role": "user", "content": "It's #A-48291"}
]
You can't just dump the full history into the prompt. Context windows are finite and long histories are expensive. Recency-weighted trimming keeps the last N turns in full, then summarizes or drops older turns. The specific budget depends on your model (8k, 32k, 128k context) and your cost targets.
| Feature | Type | Computation |
|---|---|---|
| Tokenized turn history | Sequence | Online, per request |
| Turn count | Integer | Online, incremented per turn |
| History token length | Integer | Online, computed after tokenization |
| Summarized older context | String | Online or cached per session |
Retrieval Features
When RAG is enabled, the top-k retrieved passages become features. They're ranked by cosine similarity between the query embedding and the document embeddings in your vector store, then concatenated into the prompt before the user's message.
# Retrieved passages injected into prompt context
retrieved_context = "\n\n".join([
f"[Source: {p.source}]\n{p.text}"
for p in top_k_passages # typically k=3 to k=5
])
The retrieval score itself is also a useful signal. If the top passage similarity is below a threshold (say, 0.65), you might skip RAG entirely rather than inject irrelevant context that confuses the model.
Session-Level Routing Features
These features don't go into the LLM prompt. They feed a lightweight routing layer that decides what to do with the request before the LLM ever sees it.
- Detected intent (string enum):
account_inquiry,technical_support,general_qa,off_topic. Computed by a small intent classifier running on the raw user message. - User tier (integer): free vs. paid vs. enterprise. Pulled from your user service. Determines which model variant to route to.
- Prior tool-call results (JSON): if the previous turn invoked a web search or database lookup, the result is passed forward so the model doesn't repeat the same call.
- Session abandonment risk score (float): a precomputed signal from your feature store, updated every few minutes based on recent session patterns.
Key insight: The most common failure mode in ML systems is training-serving skew. Features computed differently in batch training vs. online serving silently degrade model quality in ways that are hard to debug. Always design for consistency.
User and Document Features (Precomputed)
These are slower-moving signals that don't need to be recomputed on every request.
- User preference embedding (float[768]): computed offline from a user's conversation history using a bi-encoder. Updated daily. Stored in Redis for fast lookup.
- Document embeddings (float[768]): computed offline for every passage in your knowledge base. Stored in FAISS or Pinecone. Updated when documents change.
- User language preference (string): detected from historical messages, stored in the feature store.
Feature Computation
Batch Features
User preference embeddings and document embeddings are the main batch-computed features here. The pipeline runs on a schedule (daily for user profiles, triggered-on-change for documents):
Conversation logs (S3/GCS)
→ Spark job: aggregate per-user turn history
→ Bi-encoder inference (GPU batch job)
→ Write embeddings to offline store (Parquet)
→ Sync to online store (Redis) via Feast materialization
Document embeddings follow the same pattern but are triggered by document ingestion events rather than a fixed schedule. A new support article gets embedded within minutes of being published.
Near-Real-Time Features
Session-level signals like abandonment risk and recent tool-call patterns need to be fresher than daily. A streaming pipeline handles these:
User events (Kafka topic: session_events)
→ Flink job: windowed aggregation (last 10 minutes)
→ Compute session features per session_id
→ Write to Redis with TTL matching session lifetime
The Flink job is stateful. It maintains a per-session window of recent events and emits updated feature values whenever a new event arrives. Latency from event to feature availability is typically under 5 seconds.
Real-Time Features
Query embeddings cannot be precomputed. They're computed at request time, inline in the serving path:
# Computed synchronously during request handling
query_embedding = encoder.encode(user_message) # ~10-20ms on GPU
top_k_passages = vector_store.search(query_embedding, k=5)
intent = intent_classifier.predict(user_message) # ~5ms on CPU
The query encoder and intent classifier need to be co-located with your serving infrastructure to keep this under 30ms total. Running them as separate microservices adds network hops you can't afford on the critical path.
Feature Store Architecture
Here's how all three computation tiers connect to the two-layer feature store. The key thing to visualize is that data flows in from the left (raw events and logs), gets processed at different speeds, and lands in either the offline store (for training) or the online store (for serving).
FEATURE PIPELINE
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
DATA SOURCES COMPUTE LAYER STORAGE LAYER
───────────── ───────────── ─────────────
Conversation logs ───► Spark batch job ───► Offline Store
(S3/GCS, daily) (user embeddings, (Parquet/S3)
doc embeddings) │
│ Feast
│ materialization
Kafka: session_events ──► Flink streaming ───► Online Store
(continuous) (windowed agg, (Redis)
~5s latency) │
│ sub-10ms
Inbound user message ───► Inline (sync) reads
(per request) query encoder, │
intent classifier ▼
(~20-30ms total) INFERENCE PATH
(LLM prompt
assembly)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
TRAINING PATH: Feast point-in-time join reads from Offline Store
to reconstruct features as they existed at each training event
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Your feature store has two layers that serve different masters.
The online store (Redis) serves the inference path. It needs sub-10ms reads. You store user preference embeddings, session routing features, and user tier information here, keyed by user_id or session_id. TTLs are set per feature type: session features expire with the session, user embeddings expire after 48 hours.
The offline store (Parquet on S3, queryable via Hive or BigQuery) serves training. When you generate a training dataset, you need to reconstruct the exact feature values that were available at the time each training example was logged. This is point-in-time correct feature retrieval, and it's what Feast handles natively.
# Feast point-in-time join for training data generation
training_df = store.get_historical_features(
entity_df=conversation_logs_df, # has session_id + event_timestamp
features=[
"user_features:preference_embedding",
"user_features:tier",
"session_features:detected_intent",
]
).to_df()
Without this, you'll accidentally join features computed after the training example was logged, which leaks future information into training and causes your model to perform better in training than in production.
Preventing Training-Serving Skew
Three specific failure modes to lock down before you go to production.
First, prompt template versioning. If you change how you format the conversation history or inject retrieved passages, the model's behavior changes. Version your prompt templates and tie them to model versions in your registry. Never deploy a new prompt template against an old model checkpoint.
Second, retrieval consistency. During training, you need to retrieve passages using the same index and the same query encoder that will be used at serving time. If you train with passages retrieved by encoder v1 but serve with encoder v2, the model learned to use context that no longer looks the same. Freeze the retrieval stack during a training run.
Third, tokenizer version pinning. Tokenizers are not stable across model versions. A tokenizer change can shift token boundaries in ways that silently corrupt your conversation history formatting. Pin the tokenizer version in your serving config and validate it matches what was used during fine-tuning.
Common mistake: Candidates describe feature stores in the abstract but skip how training data is generated. Interviewers at ML-focused companies will ask "how do you make sure your training features match what you serve?" Have a concrete answer: point-in-time joins, frozen retrieval stacks, and versioned prompt templates.
Model Selection & Training
Model Architecture
Start with a rule-based baseline. Seriously. A system that pattern-matches common intents and returns templated responses is embarrassing to demo but invaluable as a benchmark. If your fine-tuned LLM can't beat a regex-driven FAQ bot on your top-20 query types, you have a data problem, not a model problem.
The real architecture decision is a three-way tradeoff:
Frozen API model (GPT-4, Claude). You get state-of-the-art quality with zero training overhead. The cost is real: at 10k concurrent sessions, API costs can run into tens of thousands of dollars per day, you have no control over model updates, and you can't fine-tune on proprietary data. Good for prototyping and low-volume internal tools.
Open-weight fine-tuned model (LLaMA 3, Mistral). This is the production choice for most teams building a serious product. You own the weights, you can fine-tune on your domain data, and inference cost drops by an order of magnitude once you're running your own GPU cluster. The tradeoff is operational complexity: you now own the training pipeline, the serving stack, and the safety layer.
Full pretraining from scratch. Don't. Unless you're OpenAI or Google DeepMind, the compute cost is prohibitive and you won't beat open-weight models that were pretrained on orders of magnitude more data than you can afford.
For a production conversational AI, the answer is almost always: start with a frozen API model to validate product-market fit, then migrate to a fine-tuned open-weight model once you have enough domain data and the cost pressure is real.
Input/Output Contract
The model's input is a structured prompt assembled from three components: the system instruction (role and behavior constraints), the conversation history (alternating user/assistant turns with role tags), and optionally retrieved passages prepended as grounding context. In token budget terms, a typical deployment allocates roughly 512 tokens for system prompt, 1,024-2,048 for history (recency-trimmed), and 1,024-2,048 for retrieved context, leaving the remainder of the context window for generation.
{
"messages": [
{"role": "system", "content": "You are a helpful customer support agent for Acme Corp..."},
{"role": "user", "content": "What's your return policy?"},
{"role": "assistant", "content": "Our return policy allows..."},
{"role": "user", "content": "What if the item was a gift?"}
],
"retrieved_context": [
{"passage_id": "doc_42", "text": "Gift returns require a gift receipt...", "score": 0.91}
],
"max_new_tokens": 512,
"temperature": 0.7
}
Output is a stream of tokens. The model doesn't output a score or a classification; it generates text autoregressively. Any downstream routing decisions (did the model invoke a tool? did it refuse?) are parsed from the generated text or from structured output mode if your serving stack supports it.
Common mistake: Candidates describe the model as if it outputs a single response object. In production you're streaming tokens via SSE or WebSocket. The architecture has to account for that from day one, not as an afterthought.
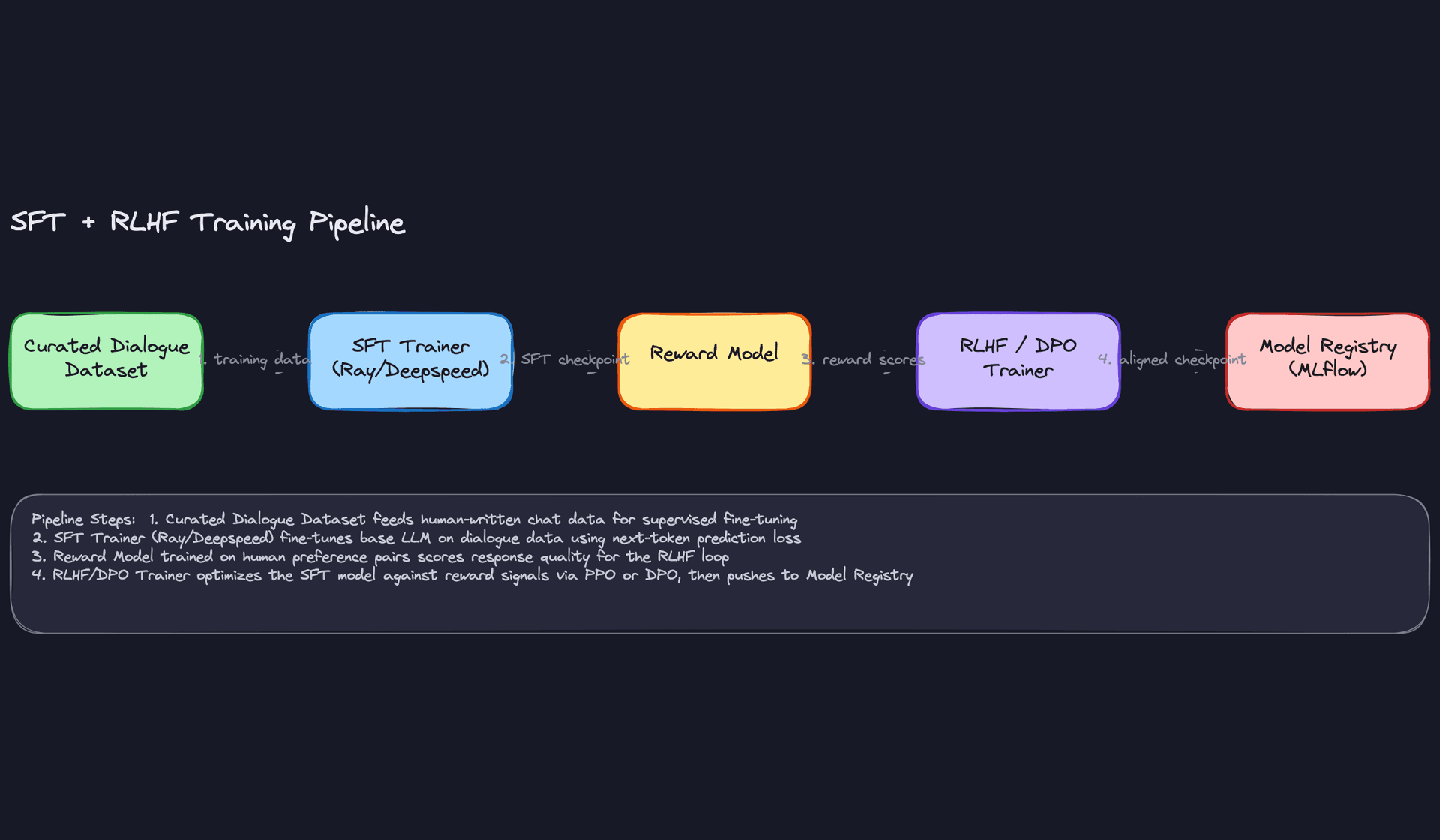
Fine-Tuning Strategy
The training pipeline has two distinct phases, and conflating them is a common interview mistake.
Phase 1: Supervised Fine-Tuning (SFT). You take a pretrained base model and fine-tune it on curated dialogues using standard next-token cross-entropy loss. The goal is behavioral: teach the model to respond in your product's tone, follow your instruction format, and handle your domain's vocabulary. Your training examples are (prompt, ideal response) pairs, either human-written or filtered from production logs.
Full fine-tuning updates every parameter. For a 7B model on 8xA100s, that's feasible. For a 70B model, you need LoRA or QLoRA. LoRA freezes the base weights and trains low-rank adapter matrices injected into the attention layers, typically with rank 8-64. You get 90%+ of the quality at 1-5% of the trainable parameter count. QLoRA adds 4-bit quantization of the frozen base, letting you fine-tune a 70B model on a single 80GB A100.
Phase 2: Alignment (RLHF or DPO). SFT teaches the model to imitate. Alignment teaches it to be preferred. You collect human preference data: pairs of responses to the same prompt, labeled with which is better. Then you either train a reward model and optimize against it with PPO (RLHF), or skip the reward model entirely and use Direct Preference Optimization (DPO), which frames alignment as a classification problem over preference pairs.
DPO is almost always the right call for teams without a dedicated RL infrastructure team. It's more stable, cheaper to run, and achieves comparable alignment quality on most tasks.
RAG-Aware Training
Here's something many candidates miss: if you're deploying with RAG, you need to train with RAG. A model that was fine-tuned on plain dialogues will often ignore retrieved context at inference time, or worse, contradict it. The fix is straightforward: during SFT data preparation, run your retriever over each training example and prepend the top-k passages to the prompt. The model learns that retrieved context is authoritative and that its job is to synthesize and cite it, not to generate from parametric memory alone.
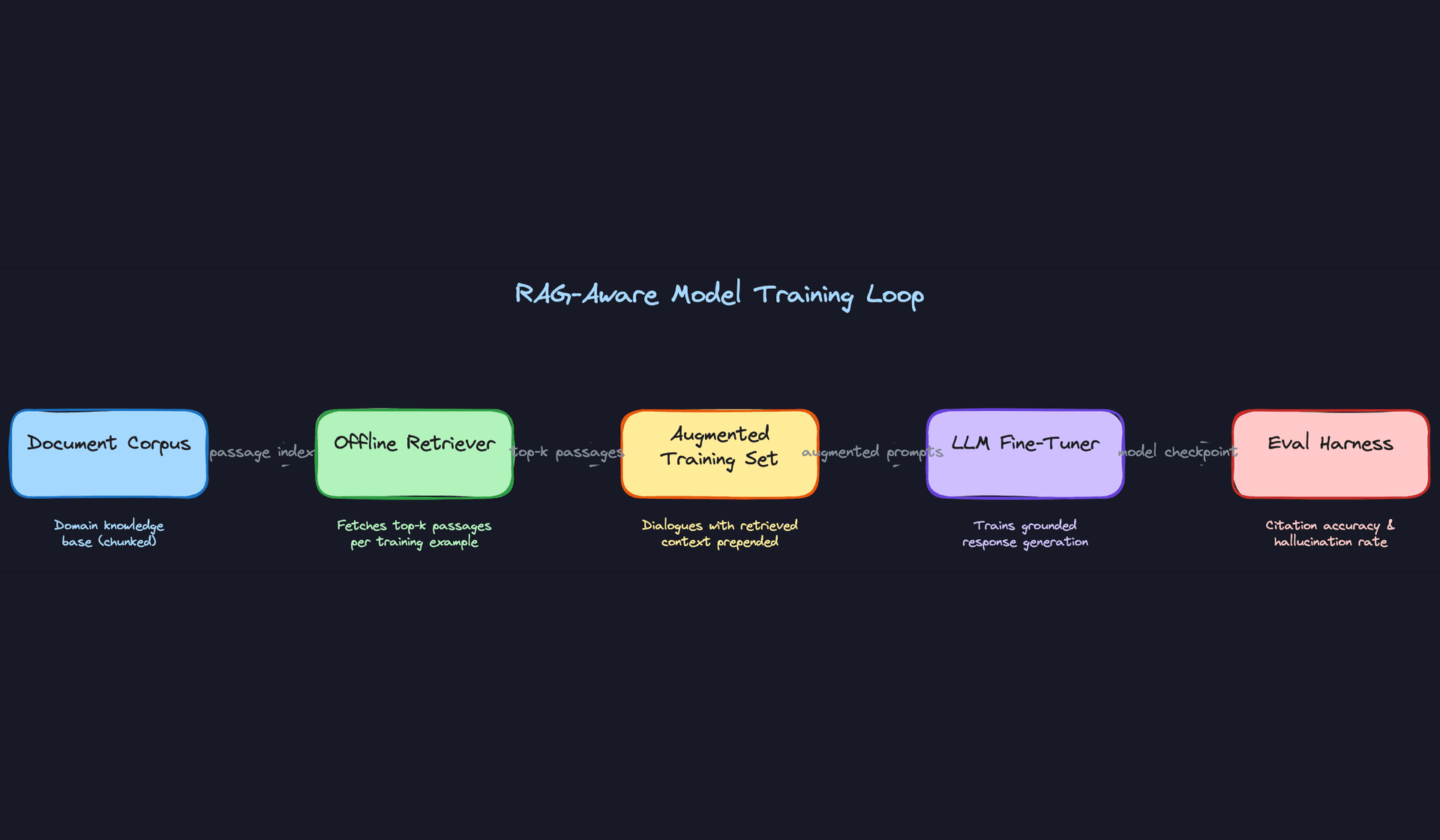
This also catches a subtle training-serving skew issue. If your retriever changes between training and serving (different index, different embedding model, different top-k), the model's behavior can degrade in ways that are hard to diagnose. Lock the retriever version alongside the model version.
Key insight: Training-serving skew in RAG systems is one of the most common production failure modes. The retriever, the embedding model, the prompt template, and the tokenizer all need to be versioned together. Change one without the others and you've silently broken the system.
Training Infrastructure
For SFT on a 7B model, 4-8x A100 80GB GPUs with DeepSpeed ZeRO Stage 2 or 3 is the standard setup. Ray Train handles distributed job orchestration cleanly and integrates well with HuggingFace Transformers. For 70B models with QLoRA, a single 80GB A100 is sufficient for fine-tuning, but you'll want multiple nodes for reasonable throughput.
Training schedule depends on how fast your data distribution shifts. For a customer support bot, a weekly fine-tuning cadence on the previous week's production logs (filtered and labeled) is a reasonable starting point. Full retraining from the base model is expensive and usually unnecessary; incremental fine-tuning on new data with a small learning rate is sufficient for most domain drift scenarios.
One thing to watch: catastrophic forgetting. If you fine-tune aggressively on new data, the model can lose capabilities it had from the previous checkpoint. Mixing a small percentage of older training data into each incremental run (replay-based fine-tuning) mitigates this.
Hyperparameter tuning for LLM fine-tuning is narrower than you might expect. Learning rate (1e-5 to 5e-5 for SFT), batch size, and LoRA rank are the main levers. Use W&B sweeps or Optuna for a small grid search, but don't over-invest here. The quality of your training data matters far more than hyperparameter precision.
Interview tip: When asked about training infrastructure, don't just list tools. Explain the constraint that drives the choice. "We use QLoRA because fine-tuning a 70B model with full precision requires 8x A100s we don't have" is a much stronger answer than "we use QLoRA for efficiency."
Offline Evaluation
Before any model touches production traffic, it needs to clear a gauntlet of offline evaluations. "It has good perplexity" is not a promotion criterion.
Automated benchmarks. MT-Bench tests multi-turn instruction following across eight categories (reasoning, coding, math, etc.) using GPT-4 as a judge. TruthfulQA measures whether the model generates factually accurate responses on questions where humans commonly hallucinate. Run both against your candidate model and the current production model. If your candidate regresses on either, it doesn't ship.
Grounding and citation accuracy. For a RAG system, measure what fraction of responses correctly cite retrieved passages versus fabricate information not present in the context. A simple heuristic: extract claims from the generated response and check whether each claim is entailed by at least one retrieved passage. Automated NLI models (e.g., a fine-tuned DeBERTa) can do this at scale.
Safety evaluation. Run the model through your red-team prompt suite: jailbreak attempts, prompt injection, PII extraction probes, and policy violation categories. Track the violation rate as a hard gate. A model that's 5% better on MT-Bench but has a 2x higher jailbreak success rate is not an improvement.
Human preference eval. Sample 200-500 prompt/response pairs from your test set and run a blind preference study: show human raters the candidate model's response and the current production model's response (order randomized) and ask which is better. Win rate above 50% with statistical significance is your promotion threshold.
Tip: Interviewers want to see that you evaluate models rigorously before deploying. "It has good AUC" is not enough. Discuss calibration, fairness slices, and failure modes. For a conversational AI specifically, that means: does it perform equally well across user demographics? Does it degrade on long conversations? Does it handle adversarial inputs gracefully?
Error analysis. Cluster your model's failures before you try to fix them. Common failure modes in conversational AI fall into a few buckets: context dropout (the model ignores earlier turns in a long conversation), retrieval mismatch (the retrieved passages are relevant but the model fails to synthesize them correctly), over-refusal (the model refuses benign requests due to over-cautious safety tuning), and hallucination on out-of-domain queries where the retriever returns low-quality results. Each failure mode has a different fix. Context dropout is a training data problem. Retrieval mismatch is a retriever quality problem. Over-refusal is an alignment calibration problem. Hallucination on low-quality retrieval is a confidence modeling problem. Knowing which bucket your errors fall into is what separates a senior engineer's answer from a junior one.
Experiment tracking. Every training run should log: perplexity on held-out validation set, reward model score distribution on sampled responses, safety eval pass rate, MT-Bench score, and human preference win rate. W&B or MLflow both work; the important thing is that you can compare any two runs side by side and trace exactly which data, hyperparameters, and code version produced each checkpoint. Reproducibility is non-negotiable when you're debugging a quality regression at 2am.
Inference & Serving
Conversational AI has one of the most demanding serving profiles in ML. You're running autoregressive generation (slow by nature), retrieval over a large corpus, and real-time safety checks, all while a user is watching a cursor blink. Getting this right is what separates a demo from a product.
Serving Architecture
Online vs. batch inference
This is an online inference system, full stop. The user is waiting for a response in real time. Batch inference has no role in the primary serving path, though you can use it offline for things like pre-embedding new documents into the retrieval corpus or scoring sampled responses with a reward model for monitoring.
Model serving infrastructure
The serving stack splits naturally into two tiers. The LLM itself runs on vLLM or Text Generation Inference (TGI). Both support PagedAttention, which treats the KV cache like virtual memory and dramatically improves GPU utilization under concurrent load. vLLM also supports continuous batching, meaning it doesn't wait for a full batch to fill before starting generation. That matters a lot when request arrival is bursty.
The auxiliary models (intent classifier, safety scorer, reward model) are much smaller and run on Triton Inference Server or TFServing. These are CPU-friendly, low-latency, and don't need the specialized LLM runtime. Keep them on a separate CPU node pool so they don't compete for GPU memory with the main model.
If you're calling a hosted API (GPT-4, Claude) instead of running open weights, your serving infrastructure simplifies significantly, but you lose control over latency, cost at scale, and fine-tuning. Be ready to justify that tradeoff explicitly.
Key insight: vLLM's continuous batching is what makes high-concurrency LLM serving practical. Without it, a single long-running generation blocks the GPU for everyone else in the queue.
Request flow end-to-end
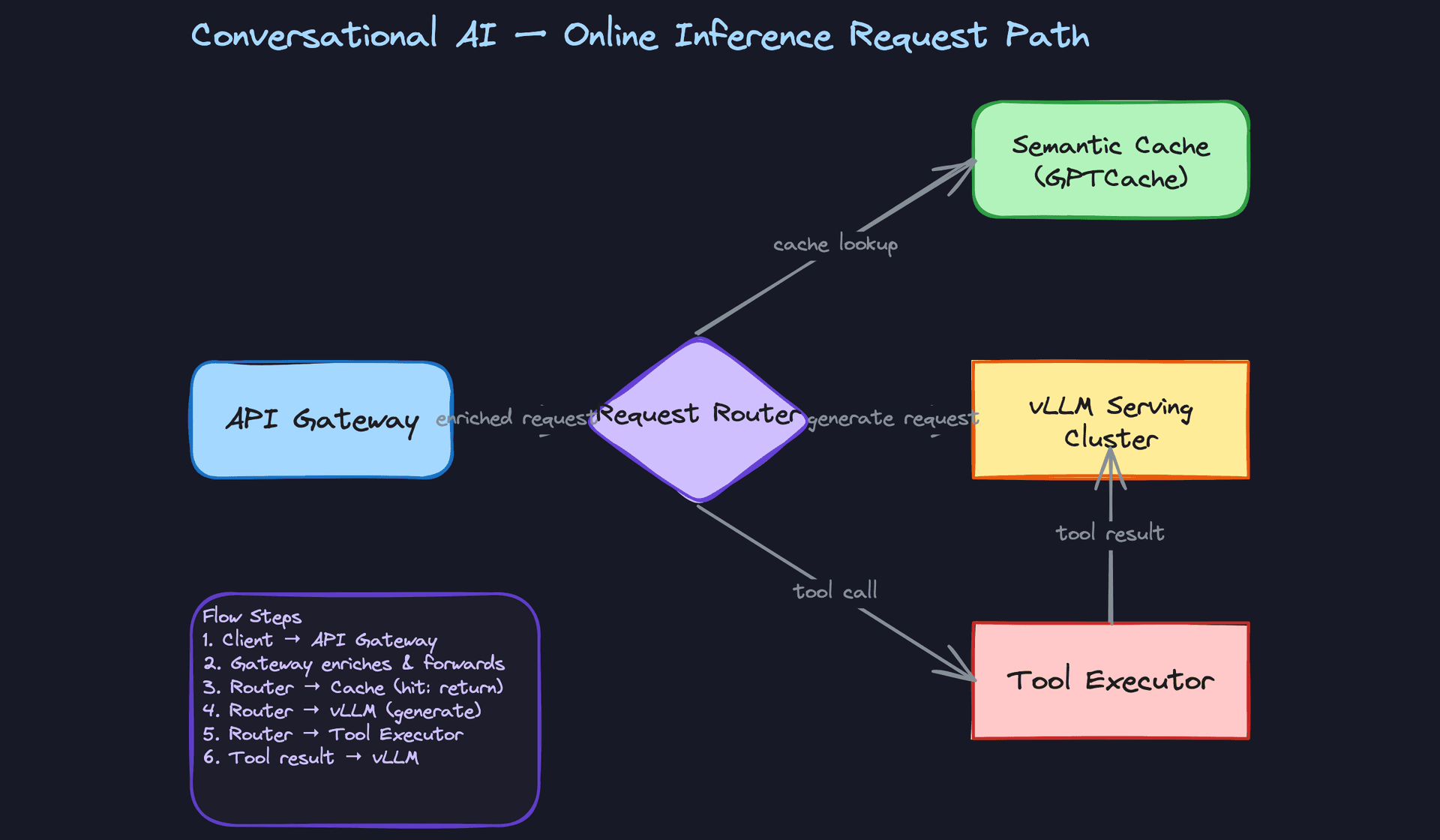
Here's what happens when a user sends a message:
- The API gateway authenticates the request, enforces rate limits, and establishes an SSE or WebSocket connection for streaming.
- The request router runs a fast intent classification (CPU, ~5ms) to decide: is this a cacheable FAQ? Does it need a tool call? Or does it go straight to the LLM?
- If the semantic cache has a high-similarity match (cosine similarity above a threshold, e.g. 0.97), it returns the cached response immediately.
- Otherwise, the RAG path fires: the query gets encoded to a dense vector, the vector store returns top-k passages, and the prompt assembler merges history, retrieved context, and session features into the final prompt.
- The assembled prompt goes to vLLM, which starts streaming tokens back through the API gateway to the client.
- In parallel, the safety classifier runs on each generated chunk and can halt the stream if a violation is detected.
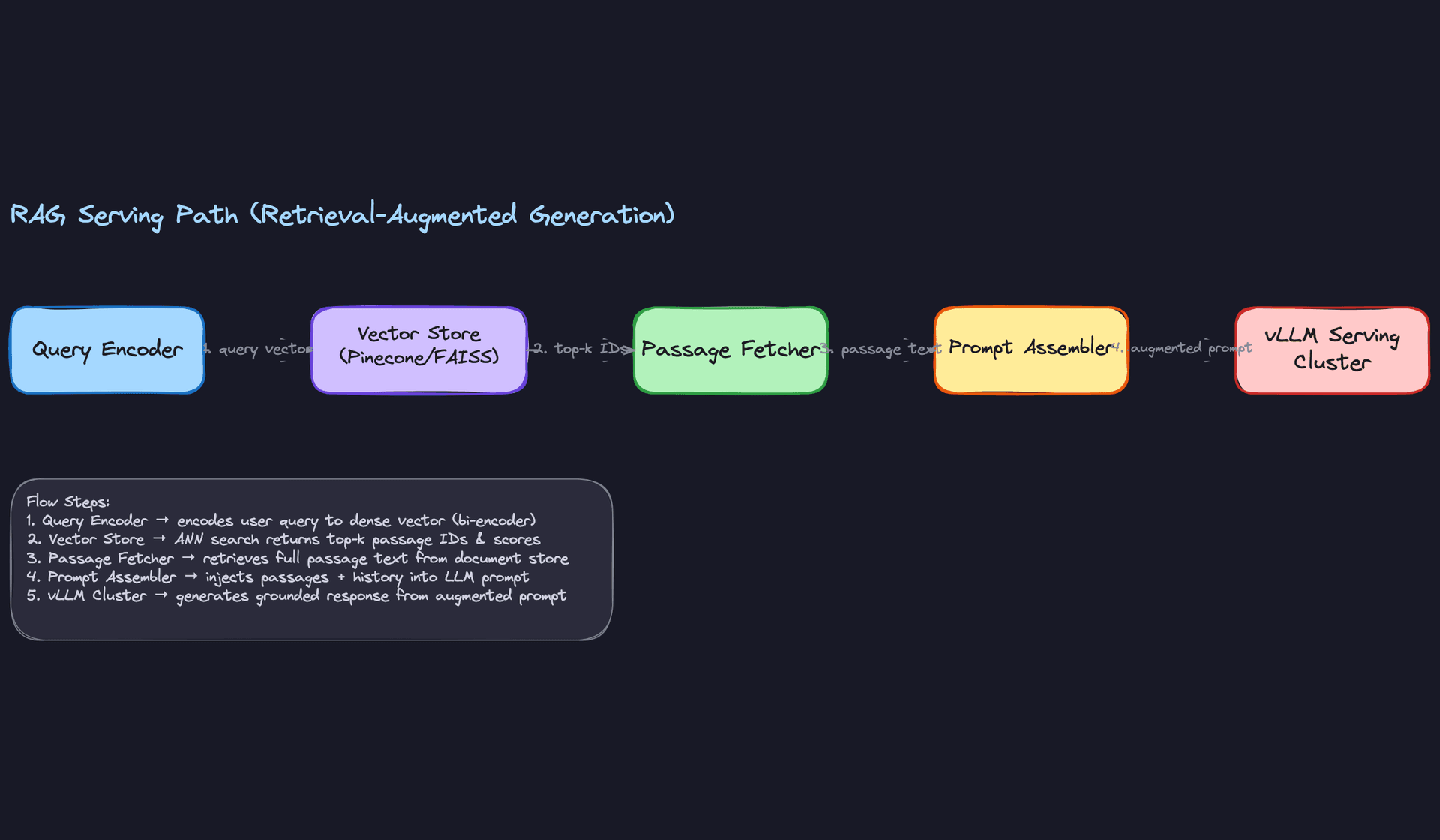
Latency breakdown
For a p50 target of first token under 500ms, you need to account for every hop:
| Stage | Typical budget |
|---|---|
| Auth + routing + intent classification | 10-20ms |
| Query embedding (online bi-encoder) | 20-40ms |
| ANN vector search (Pinecone/FAISS) | 10-30ms |
| Prompt assembly | 5-10ms |
| LLM time-to-first-token (TTFT) | 200-400ms |
| Safety check per chunk | 5-15ms |
The LLM TTFT dominates. Reducing prompt length, using KV-cache prefix reuse for shared system prompts, and keeping the model on warm GPU instances are your biggest levers here.
Common mistake: Candidates often ignore the retrieval latency and treat the LLM as the only bottleneck. In a RAG system, a slow vector store or a cold embedding model can easily add 200ms before the LLM even sees the prompt.
Optimization
Model optimization
For open-weight models, quantization is your first move. INT8 or FP8 quantization with bitsandbytes or vLLM's built-in quantization cuts memory by roughly half with minimal quality loss on most tasks. For more aggressive compression, GPTQ or AWQ give you 4-bit quantization with better quality preservation than naive INT4.
Distillation is a longer-term play: train a smaller student model on outputs from a larger teacher. This is how you get a 7B model that behaves closer to a 70B on your specific domain. It requires a good training pipeline and evaluation harness, but the serving cost reduction is substantial.
KV-cache prefix reuse is often overlooked. If every request starts with the same system prompt (which is common in customer support bots), vLLM can cache the KV activations for that prefix and skip recomputing them. For a 2000-token system prompt, this saves real time on every request.
Batching strategies
Continuous batching (vLLM's default) is the right strategy here. It allows new requests to join an in-progress batch as soon as a slot opens, rather than waiting for all sequences to finish. This keeps GPU utilization high even with variable-length outputs.
For the auxiliary models on Triton, dynamic batching with a max-wait of 5-10ms works well. The latency hit is small and the throughput gain is significant.
Interview tip: If the interviewer asks how you'd handle a 10x traffic spike, the answer isn't "add more GPUs" alone. Talk about request queuing with KEDA autoscaling on queue depth, semantic caching to absorb repeated queries, and graceful degradation (shorter context window, skip retrieval) under load.
GPU vs. CPU serving
The LLM must run on GPU. Even a quantized 7B model is too slow on CPU for interactive use. But over-provisioning GPU is expensive, so you want high utilization. Target 70-80% GPU memory utilization with vLLM's memory management.
The retrieval path (embedding model, vector search) can run on CPU if you use a small bi-encoder (e.g. a 110M parameter MiniLM). FAISS with HNSW indexing is fast enough on CPU for most workloads. This keeps your GPU budget focused on generation.
Fallback strategies
When the primary LLM cluster is overloaded or unavailable, you need a degradation plan. A tiered fallback works well: first try the primary model, then fall back to a smaller/faster model (e.g. a distilled 7B instead of a 70B), then fall back to a retrieval-only response that returns the top passage without generation, then surface a canned "I'm having trouble right now" message.
Don't just return a 503. Users tolerate a slightly worse answer far better than a hard error.
Online Evaluation & A/B Testing
Traffic splitting and experiment assignment
Assign users to experiment buckets at the session level, not the request level. If a user gets model A on their first message, they should stay on model A for the whole conversation. Request-level assignment creates incoherent multi-turn experiences and poisons your metrics.
Use a consistent hash of the user ID (or session ID for anonymous users) to assign buckets. This ensures the same user always lands in the same variant and makes the experiment reproducible.
Online metrics and statistical methodology
The metrics that matter most for a conversational AI are:
- Session completion rate: did the user accomplish their goal without abandoning or escalating?
- Thumbs-up/down rate: explicit feedback, noisy but direct.
- Escalation-to-human rate: for customer support bots, this is the clearest signal of failure.
- Session length and turn count: a proxy for engagement, but be careful. Longer sessions can mean either "the user is engaged" or "the model is failing to answer and the user keeps rephrasing."
Run a two-proportion z-test for binary metrics (completion rate, thumbs rate) and a Mann-Whitney U test for non-normal continuous metrics (session length). Don't call significance until you've hit your pre-registered sample size. Peeking early inflates false positive rates.
Common mistake: Using BLEU or ROUGE as your primary online metric. These measure surface-level text similarity, not whether the user got what they needed. They're useful offline, but online you need behavioral signals.
Ramp-up and rollback
Start at 1% traffic to catch catastrophic failures (safety violations, latency regressions, error spikes) before they affect most users. If the 1% canary looks healthy after 30 minutes, ramp to 5%, then 10%, then 25%, then 50%, then 100%. Each step should have an automated health check gate.
Define your rollback triggers before you start the ramp. Common ones: safety violation rate increases by more than 0.5 percentage points, p99 latency exceeds 8 seconds, or session abandonment rate increases by more than 2 percentage points. If any trigger fires, the system rolls back automatically without waiting for human review.
Interleaving
Interleaving is most valuable for ranking systems where you're comparing two ranked lists. For a conversational AI, it's less natural since responses aren't a ranked list. That said, if you're comparing two retrieval strategies, you can interleave retrieved passages from both systems in a single response and track which passages the model cites or which the user engages with. It's a niche technique here but worth mentioning if the interviewer pushes on retrieval quality evaluation.
Deployment Pipeline
Key insight: The deployment pipeline is where most ML projects fail in practice. A model that can't be safely deployed and rolled back is a model that won't ship.
Validation gates
Before any model touches production traffic, it has to pass a gauntlet of automated checks. At minimum:
- Offline benchmark regression: the new model must match or beat the current production model on MT-Bench, your internal domain eval set, and TruthfulQA. A drop of more than 2% on any benchmark blocks promotion.
- Safety eval: run the full red-team prompt suite. Zero tolerance for new jailbreak failures that the current model handles correctly.
- Latency regression: p99 TTFT on a synthetic load test must stay within 10% of the current model's baseline.
- Shadow scoring: the new model runs in shadow mode (receives all production traffic but responses are discarded) for 24 hours. Reward model scores and safety violation rates are compared against the live model.
Only after all gates pass does the model enter the canary phase.
Canary deployment
Route 1% of production traffic to the new model. Keep both the old and new model warm and running. The canary phase is not just about catching bugs; it's about collecting real behavioral data at small scale before you commit.
Use feature flags (not just Kubernetes traffic weights) to control the rollout. Feature flags let you target specific user segments (e.g. internal employees first, then beta users, then general population) and roll back instantly without a redeployment.
Shadow scoring
Shadow mode deserves its own emphasis. Run the new model on every request in parallel with the production model, but only return the production model's response to the user. Log both responses and score them with your reward model and safety classifier. This gives you a statistically significant quality comparison before any user sees the new model's output.
The cost is roughly 2x inference cost during the shadow period. For a high-stakes model update, that's worth it.
Rollback triggers
Automated rollback should be non-negotiable. Manual rollback processes fail because engineers are asleep, in meetings, or slow to respond. Wire your monitoring directly to your deployment controller.
# Example rollback trigger logic (simplified)
ROLLBACK_THRESHOLDS = {
"safety_violation_rate_delta": 0.005, # +0.5pp vs baseline
"session_abandonment_rate_delta": 0.02, # +2pp vs baseline
"p99_ttft_ms": 8000, # absolute ceiling
"error_rate": 0.01, # 1% hard errors
}
def should_rollback(current_metrics: dict, baseline_metrics: dict) -> bool:
if current_metrics["p99_ttft_ms"] > ROLLBACK_THRESHOLDS["p99_ttft_ms"]:
return True
if current_metrics["error_rate"] > ROLLBACK_THRESHOLDS["error_rate"]:
return True
delta_safety = (
current_metrics["safety_violation_rate"]
- baseline_metrics["safety_violation_rate"]
)
if delta_safety > ROLLBACK_THRESHOLDS["safety_violation_rate_delta"]:
return True
return False
If should_rollback returns true, the system shifts 100% of traffic back to the previous model version within seconds. The new model stays deployed but receives zero traffic, so you can debug without pressure.
Monitoring & Iteration
Most candidates design a great launch. Staff-level candidates design a system that gets better after launch. The difference shows up entirely in this section.
Production Monitoring
Data Monitoring
The first thing to watch is whether your inputs still look like what the model was trained on. For a conversational AI, that means tracking the embedding distribution of incoming queries. Compute a baseline centroid from your training set and measure cosine distance or MMD (Maximum Mean Discrepancy) against a rolling window of live traffic. A sudden shift often means a new user segment found your product, a downstream app changed how it formats requests, or a news event is driving a topic spike your model has never seen.
Schema violations are simpler but just as dangerous. If your prompt assembler expects a conversation_history field and it arrives null, the model silently generates a context-free response with no error thrown. Validate every field at the feature serving layer before it reaches the prompt assembler, and emit a metric when you drop or impute a field.
Common mistake: Candidates monitor model outputs but forget to monitor model inputs. By the time output quality degrades, the root cause is often a data pipeline change that happened days earlier.
Retrieval quality deserves its own signal. Sample a few hundred queries per day, run them through your retriever, and compute Mean Reciprocal Rank (MRR) against a held-out relevance set. If your document corpus was updated and the new chunks are poorly segmented, retrieval quality tanks before generation quality does.
Model Monitoring
Online quality signals are your fastest feedback. Track thumbs-up/down rate, session abandonment rate (user closes the window mid-conversation), task completion rate, and escalation-to-human rate. These are noisy individually but powerful in aggregate. A 3-point drop in task completion rate on a Tuesday afternoon is a real signal.
For output distribution shift, watch response length, refusal rate, and topic distribution. If your model suddenly starts refusing 40% of requests that it previously answered, something changed, either a safety classifier threshold, a prompt template update, or a model rollout that didn't get properly validated. Refusal rate is one of the most sensitive canaries you have.
Offline, run your reward model over a random sample of live responses daily. You don't need to score everything. Scoring 1,000 responses per day gives you a statistically stable trend line and costs almost nothing compared to your serving bill.
System Monitoring
Track p50, p95, and p99 latency for time-to-first-token and total response time separately. They fail for different reasons. Time-to-first-token spikes usually point to GPU queue depth or KV-cache pressure. Total response time spikes often point to retrieval latency or a long-tail generation on a complex query.
GPU utilization should sit between 70-85% under normal load. Below 60% means you're over-provisioned and burning money. Above 90% sustained means you're one traffic spike away from queue buildup and cascading latency. Set alerts at both ends.
Error rates to track: model timeout rate, retrieval failures, tool execution failures, and safety classifier failures (which should fail closed, not open).
Alerting Thresholds
Don't alert on every metric. You'll get alert fatigue and people will start ignoring pages. Tier your alerts:
- P0 (page immediately): safety violation rate spikes more than 2x baseline, error rate above 5%, time-to-first-token p99 above 3 seconds
- P1 (investigate within the hour): thumbs-down rate up 20% over 24-hour rolling average, retrieval MRR drops below threshold, GPU utilization sustained above 90%
- P2 (review in daily standup): gradual embedding drift crossing MMD threshold, reward model score trending down over 7 days
The P2 alerts are where most of the interesting work happens. They're slow-moving problems that don't feel urgent until they suddenly are.
Feedback Loops
User feedback is the most valuable signal you have, and also the most delayed and biased. Thumbs-up/down is immediate but sparse. Most users never rate anything. Session abandonment is implicit but noisy. Task completion is the gold standard but requires defining what "complete" means per use case.
Getting Feedback Back Into Training
The pipeline looks like this: every request and response gets logged to a data lake (with user consent and PII stripped). Feedback events, thumbs ratings, abandonment signals, escalations, join against those logs on session ID. That joined dataset becomes your candidate pool for new fine-tuning examples.
Don't feed everything back. Filter aggressively. Keep responses with explicit positive ratings. Keep sessions where the user completed their task. Keep escalated sessions as negative examples. Deduplicate by semantic similarity so you're not overweighting common queries. What's left is a high-quality slice that actually improves the model.
def filter_for_flywheel(session_logs, feedback_events, min_quality_score=0.7):
"""
Join session logs with feedback, apply quality filters,
return curated (prompt, response) pairs for fine-tuning.
"""
joined = session_logs.join(feedback_events, on="session_id", how="left")
positive = joined[
(joined["thumbs_up"] == True) |
(joined["task_completed"] == True) |
(joined["reward_model_score"] >= min_quality_score)
]
negative = joined[joined["escalated_to_human"] == True]
# Deduplicate by embedding similarity
positive_deduped = semantic_dedup(positive, threshold=0.95)
return positive_deduped, negative
Handling Feedback Delay
Some feedback signals arrive immediately. Others take days. A user might complete a task they started in your chat session by calling your support line three days later, and you'd never know the conversation failed.
For delayed labels, use a few strategies. First, set a collection window per feedback type: implicit signals (abandonment) close after 30 minutes, explicit ratings close after 7 days, downstream outcome signals (did the user churn?) close after 30 days. Don't retrain until the window closes for the signal type you care about.
Second, weight recent feedback more heavily when you do retrain. Exponential decay on label timestamps prevents your model from being dominated by month-old behavior patterns.
Tip: When an interviewer asks about feedback loops, mention label delay explicitly. Most candidates assume feedback is instantaneous. Acknowledging the delay and having a concrete strategy for it signals senior-level thinking.
From Alert to Redeployment
When a monitoring alert fires, the diagnosis path matters as much as the fix. A drop in task completion rate could be a model regression, a retrieval failure, a prompt template bug, or a change in user behavior. You need to isolate the layer before you start retraining.
The flow: alert fires, on-call engineer checks the system monitoring dashboard to rule out infrastructure issues, then checks retrieval MRR to rule out corpus problems, then samples 50-100 failing conversations and reads them. Reading actual conversations is irreplaceable. Automated metrics tell you something is wrong; conversations tell you why.
Once you've diagnosed the root cause, the fix is usually one of: a prompt change (deploy in minutes), a retrieval corpus update (deploy in hours), or a fine-tuning run (deploy in days). Match the urgency of the fix to the severity of the problem.
Continuous Improvement
Retraining Strategy
Scheduled retraining (weekly or biweekly) works well when your data flywheel is healthy and your domain is relatively stable. You accumulate a week of production feedback, filter it, merge it with your existing training set, and kick off a fine-tuning run. Simple, predictable, easy to reason about.
Drift-triggered retraining is better when your domain evolves unpredictably. When embedding drift crosses your MMD threshold, or when reward model scores trend down for three consecutive days, an automated trigger kicks off a retraining job. This is more responsive but requires careful guardrails: you don't want a single anomalous day of traffic to trigger an unnecessary retraining run.
In practice, most mature systems use both. Scheduled retraining as the baseline cadence, drift-triggered retraining as the emergency path.
Prioritizing Improvements
Not all model improvements are equal. A rough prioritization framework:
Safety issues are always first. A model that occasionally leaks PII or produces harmful content cannot wait for the next scheduled cycle.
After safety, prioritize by impact per engineering hour. Adding a high-quality data source for a common failure mode usually beats architectural changes. A new retrieval strategy for a narrow domain might move the needle more than a full fine-tuning run. Measure everything against your core metrics before committing.
Key insight: The highest-leverage improvements early in a system's life are almost always data quality fixes, not model architecture changes. The model is usually fine. The training data is usually not.
Long-Term Evolution
In the first few months, you're mostly fighting data quality and prompt engineering. Your retrieval corpus is incomplete, your fine-tuning set is small, and your monitoring is still being calibrated.
By six months, the data flywheel starts paying off. You have enough production traffic to identify systematic failure modes, and your fine-tuning set is large enough that incremental additions move metrics. This is when you start seeing the value of the feedback loop infrastructure you built at launch.
At maturity, the interesting problems shift. Your base model quality is good enough that the gains come from routing, cost optimization, and specialization. You build a small intent classifier that routes simple queries to a cheaper, faster model and reserves your large model for complex multi-turn sessions. You start thinking about model distillation to reduce serving cost. The system architecture evolves from "one LLM does everything" to a multi-model pipeline where each component is right-sized for its task.
Tip: Staff-level candidates distinguish themselves by discussing how the system improves over time, not just how it works at launch. Talk about the data flywheel, the drift detection cadence, and how the routing architecture changes as you learn more about your traffic patterns. That's the conversation that separates a senior design from a staff design.
What is Expected at Each Level
Interviewers calibrate their expectations based on your level. Knowing where the bar sits helps you spend your time on the right problems instead of over-engineering things that don't matter at your level, or staying too shallow when depth is expected.
Mid-Level (L4/L5)
- Design the core inference path end-to-end: user request in, streamed response out, with RAG in the middle. You should be able to sketch the query encoder, vector store lookup, prompt assembly, and vLLM serving cluster without being prompted.
- State your latency and throughput targets early and refer back to them. Something like "first token under 500ms at 10k concurrent sessions" gives the whole conversation an anchor.
- Make a clear call between hosted API (GPT-4, Claude) and open-weight model (LLaMA 3, Mistral). You don't need to be right, but you need a reason. Cost, latency, data privacy, and fine-tuning control are all valid axes.
- Describe at least one quality signal from production: thumbs-up/down rate, session abandonment, or escalation-to-human rate. Showing you think about feedback at all puts you ahead of candidates who stop at model serving.
Senior (L5/L6)
- Go deep on the training pipeline. SFT on curated dialogues gets you a capable model; RLHF or DPO gets you an aligned one. Explain why you'd use DPO over PPO in a resource-constrained setting (simpler, no separate reward model rollout, less training instability).
- Training-serving skew is where senior candidates separate themselves. Prompt template changes, tokenizer version drift, and inconsistent retrieval at training versus inference time are all real failure modes. Name them and explain how you'd lock them down: versioned prompt templates, offline retrieval at data prep time, pinned tokenizer artifacts.
- Design the semantic cache and request router explicitly. Which queries hit the cache? What's your similarity threshold before you trust a cached response? When does the router invoke a tool versus going straight to the LLM? These aren't afterthoughts; they're where most of your cost savings come from.
- Distinguish offline from online metrics and explain how they connect. Reward model score and MT-Bench performance tell you something before deployment. Session completion rate and escalation rate tell you something after. A senior candidate knows neither set is sufficient alone.
Common mistake: Candidates at this level often design a great training pipeline and then describe monitoring as "we'll track accuracy." That's not enough. Name the specific signals, their collection mechanism, and what threshold triggers an alert or rollback.
Staff+ (L7+)
- Reason about cost as a first-class design constraint, not an afterthought. At 10k concurrent sessions, the difference between routing 30% of queries to a small classifier instead of the full LLM can mean millions of dollars per year in GPU costs. A staff candidate models this tradeoff explicitly and proposes a multi-model architecture: lightweight intent classifier, mid-size model for simple tasks, large model only when needed.
- Safety is architecture, not a filter bolted on at the end. At staff level, you're expected to describe a layered safety system: input filtering, output classification, policy violation alerting, and a shadow scoring pipeline that runs on every response. You should also address how safety requirements change the training pipeline (RLHF alignment, red-teaming datasets, refusal tuning).
- The data flywheel is your moat. Production traffic, filtered by quality signals and deduped, feeds back into fine-tuning on a weekly cadence. A staff candidate explains what makes a good filter (reward model score above threshold, no safety violations, user gave positive feedback), how you prevent distribution collapse from training on your own outputs, and who owns the pipeline across ML, data engineering, and product teams.
- Think about how the system evolves over months. User behavior shifts, the knowledge base goes stale, a new model version drops with different tokenization. Staff candidates describe a versioning and migration strategy: how you A/B test a new base model without disrupting existing sessions, how you refresh the RAG corpus without reindexing everything, and how you sunset old model versions without breaking downstream integrations.
Key takeaway: A conversational AI system is not a model plus an API. It's a feedback loop. The candidates who impress at every level are the ones who treat production traffic as training data, safety as infrastructure, and latency budgets as design constraints from the very first minute of the interview.
