Retrieval-Augmented Generation (RAG)
Every LLM you've ever used was frozen in time the moment training stopped. GPT-4 doesn't know about your company's internal docs. Claude can't read the support tickets from last week. And no amount of prompting changes that, because the knowledge simply isn't in the weights.
RAG is the practical fix the industry converged on. Instead of retraining or fine-tuning a model every time your knowledge base changes, you retrieve the relevant information at query time and hand it to the LLM as context. The model reads it, reasons over it, and responds as if it knew all along. Think of it as giving the LLM an open-book exam instead of expecting it to memorize everything in advance.
The mental model you need going into your interview is two systems working together: a retrieval system that finds the right documents, and a generation system (the LLM) that turns those documents into an answer. The interface between them is the context window. Get retrieval wrong and it doesn't matter how good your LLM is. The whole system fails quietly, producing confident answers grounded in the wrong evidence. That failure mode is exactly what interviewers are probing for when they push past your happy-path description.
Key insight: RAG sits at the intersection of search infrastructure, embedding models, and LLM serving. That's why AI engineer roles at OpenAI, Google, Meta, and Airbnb love it as an interview topic. It tests whether you can reason across the full stack, not just the model layer.
Candidates who only know the query-time flow get filtered out fast. The interviewers who ask about RAG want to hear about chunking decisions, embedding model consistency, retrieval quality metrics, and latency budgets across multiple inference hops. That's what this lesson covers.
How It Works
Every RAG request follows the same two-act structure: a slow offline act that happens once, and a fast online act that happens on every query. Most candidates only describe the online half. That's a mistake.
The Offline Pipeline (Before Any Query Runs)
Before a user can ask anything, you need to build the index. Your raw documents get split into chunks, each chunk gets passed through an embedding model to produce a dense vector, and those vectors get stored in a vector database like Pinecone, Weaviate, or FAISS alongside the original chunk text. That's it. But this pipeline has to run before anything else works, and it has to stay current as your documents change.
Think of it like building a library card catalog. The catalog has to exist before anyone can search it.
The Online Query Path
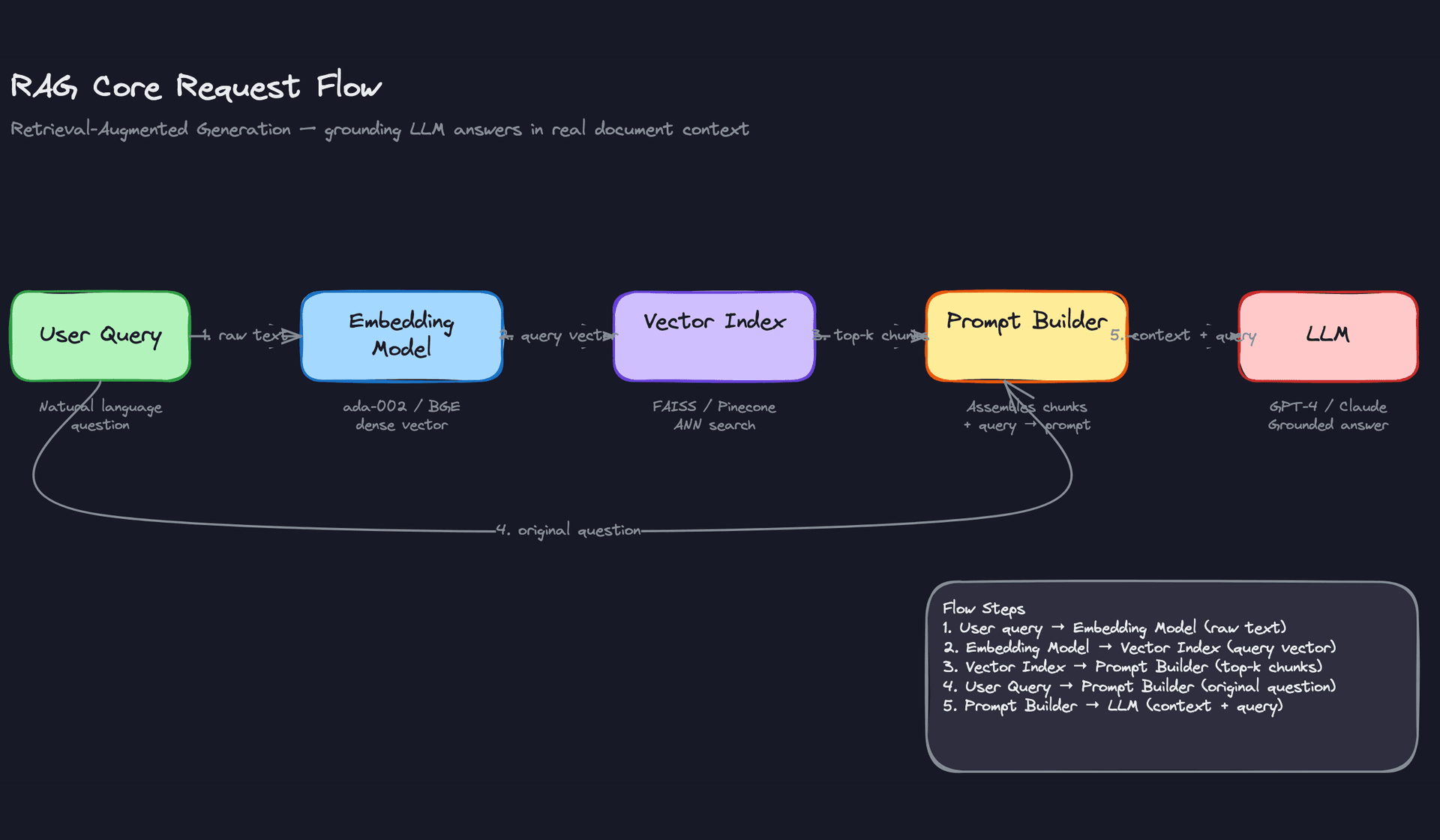
When a user query arrives, here's exactly what happens:
The query text gets passed through the same embedding model used during indexing. That produces a query vector. The vector database runs an approximate nearest-neighbor search against all stored chunk embeddings and returns the top-k most similar chunks, usually somewhere between 3 and 20. In many production systems, those candidates then pass through a re-ranker, a cross-encoder model like Cohere Rerank or a fine-tuned BERT variant that scores each chunk against the query more precisely than cosine similarity can. The re-ranker is slower than ANN search but operates on a small candidate set, so the latency cost is manageable and the relevance gain is often significant. The final ranked chunks get assembled into a prompt alongside the original question and a system instruction, something like "Answer only using the context provided." That full prompt goes to the LLM, which generates a grounded response.
Five steps, six if you include re-ranking. Each one is a potential failure point.
Here's what that flow looks like:
The Three Properties Your Interviewer Is Probing
The embedding model is a contract. The same model must be used at index time and query time. If you embed your documents with text-embedding-ada-002 and then switch to BGE for queries, your cosine similarity scores become meaningless. Retrieval silently degrades. This is training-serving skew in disguise, and interviewers at companies like Google and OpenAI will absolutely ask about it. The right answer is to version your index alongside your embedding model and trigger a full re-index whenever the model changes.
The context window is a hard constraint. The LLM doesn't see your entire document corpus. It only sees what you stuff into the prompt. That means retrieval quality directly determines generation quality. A bad retriever gives the LLM irrelevant context, and no amount of prompt engineering recovers from that. Your interviewer wants to know you understand that the LLM is downstream of retrieval, not a safety net for it. Re-ranking is one of the most direct levers you have for improving that retrieval quality without touching the LLM at all.
Latency is additive across hops. A production RAG call chains at least three network-bound operations: embedding inference (roughly 10-30ms), ANN search (roughly 10-50ms depending on index size), re-ranking if present (roughly 20-80ms on a small candidate set), and LLM generation (anywhere from 500ms to several seconds). If any one of those hops spikes, your p99 blows up. Interviewers will ask how you'd keep latency under control, and the answer starts with knowing which hop is actually the bottleneck.
Your 30-second explanation: "RAG has two parts. Offline, you chunk your documents, embed each chunk, and store the vectors in a vector database. Online, when a query comes in, you embed the query with the same model, run a nearest-neighbor search to find the most relevant candidates, optionally re-rank them with a cross-encoder for better precision, inject the top chunks into a prompt with the user's question, and send it to the LLM. The key insight is that the LLM never touches your document corpus directly. It only sees what retrieval hands it."
Common mistake: Candidates describe RAG as "just sending documents to an LLM." The vector index, the embedding model contract, and the offline pipeline are what make it a system. If you skip those in your explanation, you sound like you've only used a demo, not built anything real.
Patterns You Need to Know
In an interview, you'll usually need to pick a specific approach. Here are the ones worth knowing.
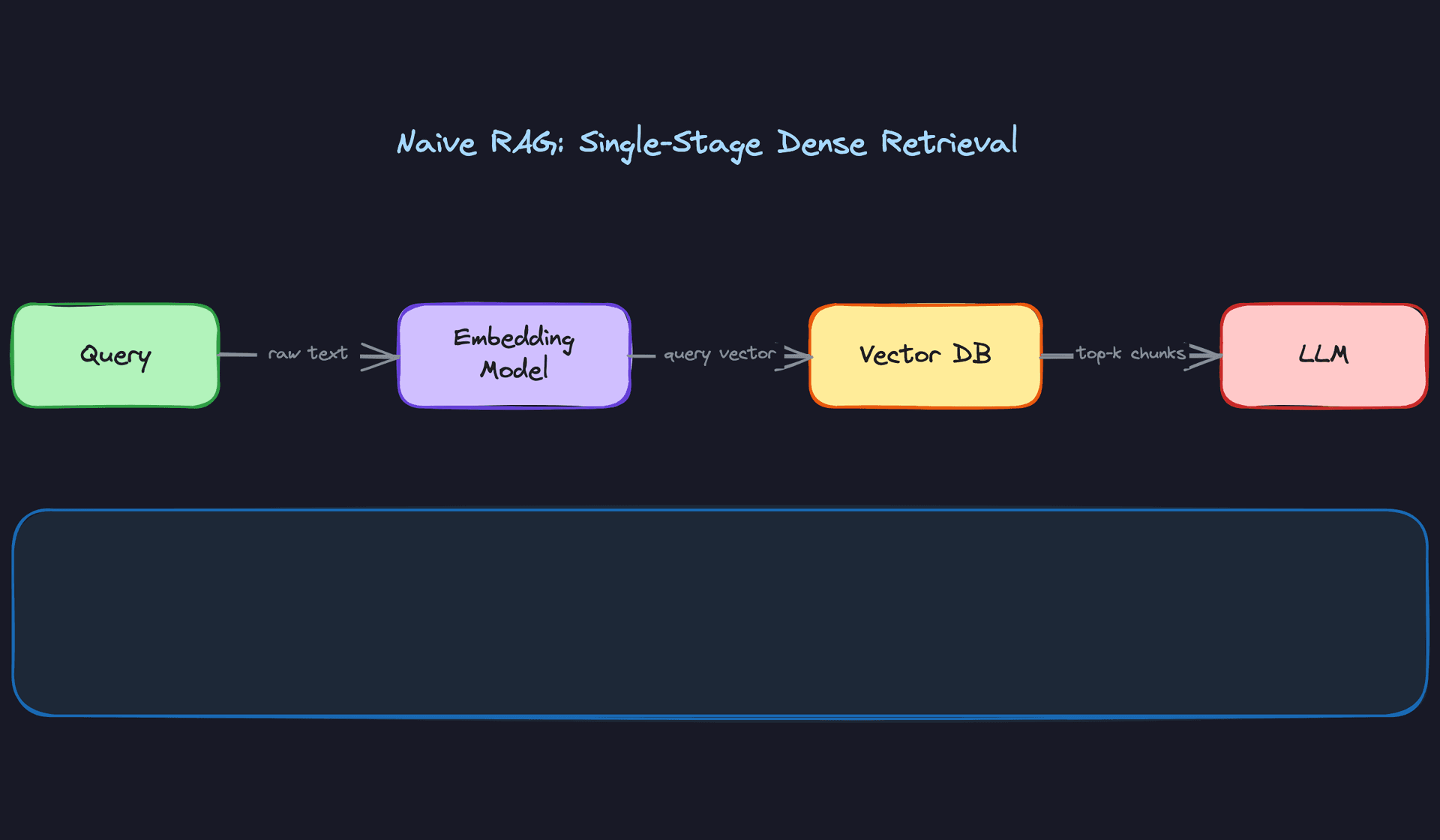
Naive RAG
This is the baseline. You take the user's query, embed it, run an approximate nearest-neighbor search against your vector index, grab the top-k chunks, and hand them to the LLM. Fixed-size chunking (say, 512 tokens with some overlap) keeps the indexing pipeline simple.
The problem shows up fast in practice. Fixed chunking splits sentences mid-thought, dense retrieval misses exact-match terms like product codes or proper nouns, and multi-hop questions (where the answer requires connecting two separate documents) fall apart entirely. Treat this as your starting point in an interview, not your final answer. If the interviewer asks "what would you build first?", Naive RAG is a reasonable answer. If they ask "what would you ship to production?", it's not.
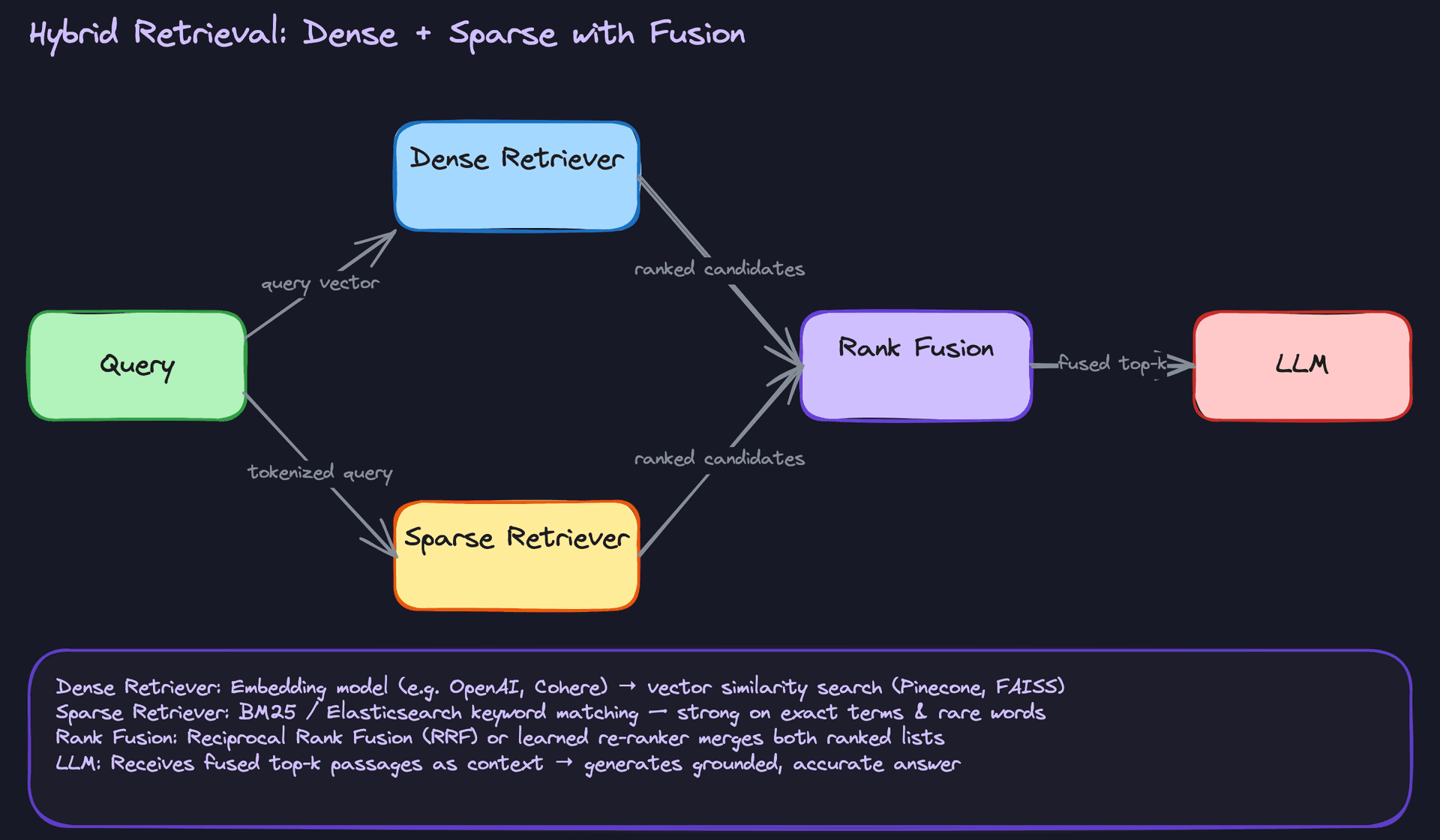
Hybrid Retrieval
Dense vector search is great at semantic similarity but terrible at exact matches. BM25 is great at exact matches but blind to paraphrasing. Hybrid retrieval runs both in parallel and merges the results, typically via reciprocal rank fusion (RRF) or a learned re-ranker that scores the combined candidate list.
This is what most production systems actually use. If someone asks "what's the refund policy for order #A4821-XZ?", dense search might return vaguely relevant policy documents while BM25 locks onto that order number directly. You need both signals. When an interviewer asks how you'd handle a corpus with a mix of technical documentation and free-form text, hybrid retrieval is the answer to reach for.
Interview tip: When you mention hybrid retrieval, name the fusion mechanism. "I'd use reciprocal rank fusion to merge the ranked lists before passing to the LLM" signals you've actually thought about the plumbing, not just the concept.
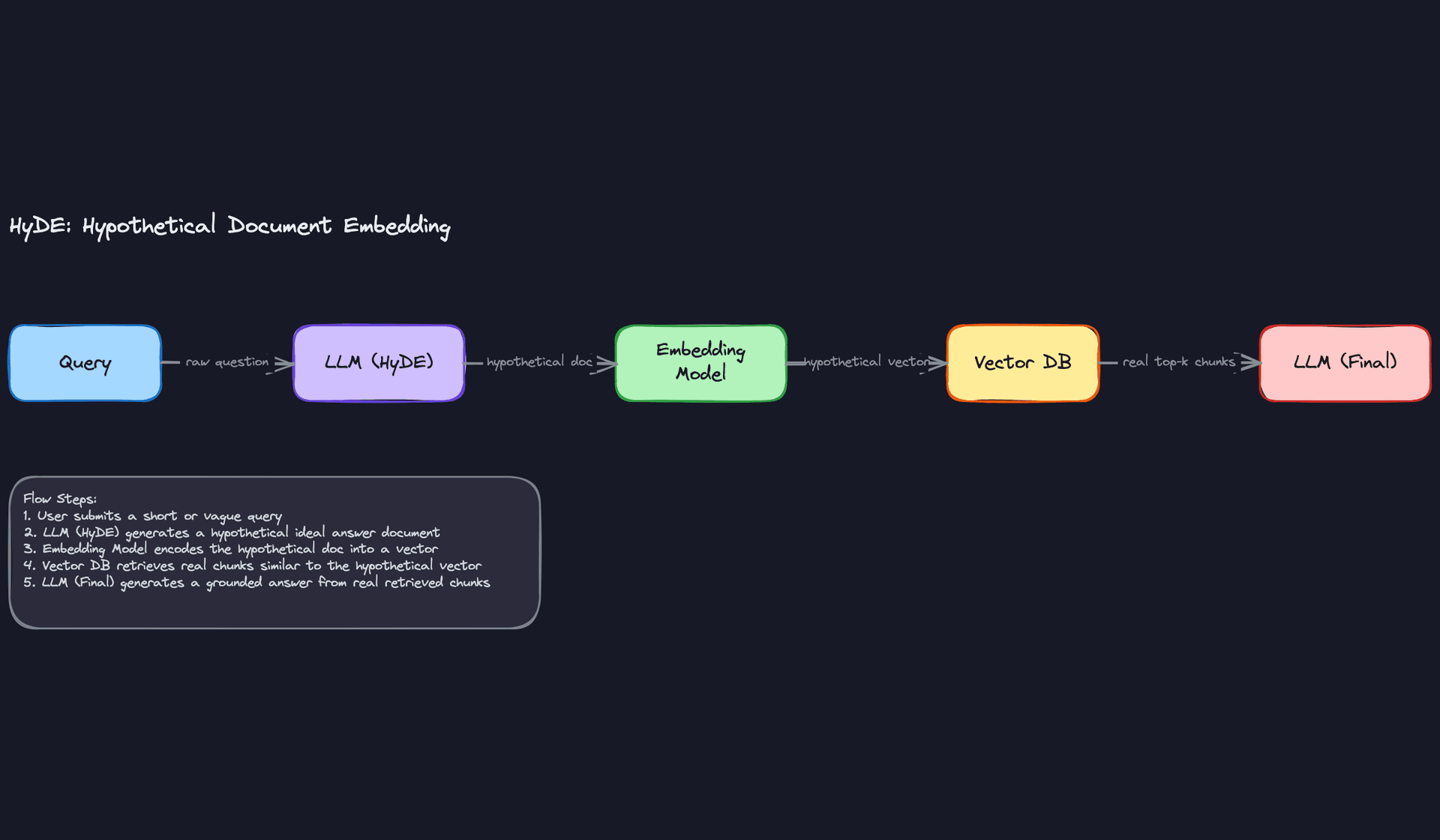
HyDE (Hypothetical Document Embeddings)
Short or vague queries are a retrieval nightmare. "Tell me about the new compliance rules" doesn't embed into a vector that's close to any specific document. HyDE sidesteps this by asking the LLM to generate a hypothetical ideal answer first, then embedding that answer and using it as the retrieval query.
The intuition is that a well-formed hypothetical answer lives in a similar vector space to real documents that contain the actual answer, even if the original query didn't. Recall improves significantly on short queries. The tradeoff is an extra LLM call before retrieval even starts, which adds latency and cost. Reach for this when your users tend to ask short, ambiguous questions and retrieval quality is the bottleneck.
Common mistake: Candidates sometimes describe HyDE as "asking the LLM to answer first." That's not quite right. The hypothetical answer is never shown to the user. It's only used as a retrieval probe. Be precise about this distinction.
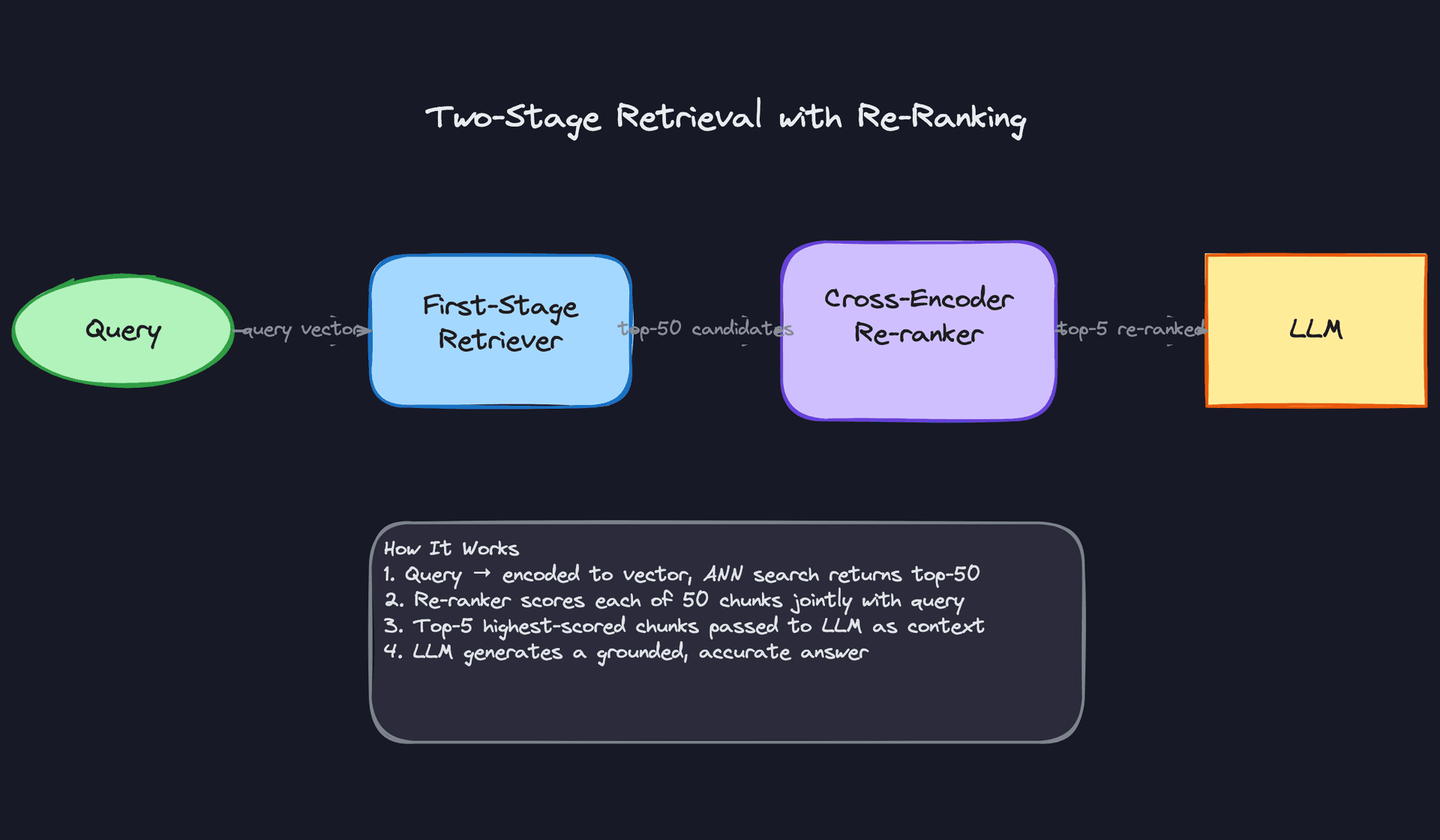
Two-Stage Retrieval with Re-Ranking
The core idea here is that fast retrieval and precise retrieval are different problems. Your first-stage retriever (ANN search over your vector index) is optimized for speed, not accuracy. It returns 50 candidates in ~20ms. Then a cross-encoder re-ranker, something like Cohere Rerank or a fine-tuned BERT model, looks at each candidate alongside the original query jointly and scores them. You pass the top 5 to the LLM.
Why does joint scoring matter? A bi-encoder embeds the query and document independently, so it can't capture fine-grained interactions between them. A cross-encoder sees both at once, which makes it much more accurate but also much slower. Running it on 50 candidates instead of your full index is what makes this practical. This pattern is worth proposing any time the interviewer pushes on retrieval precision or mentions that users are getting irrelevant answers.
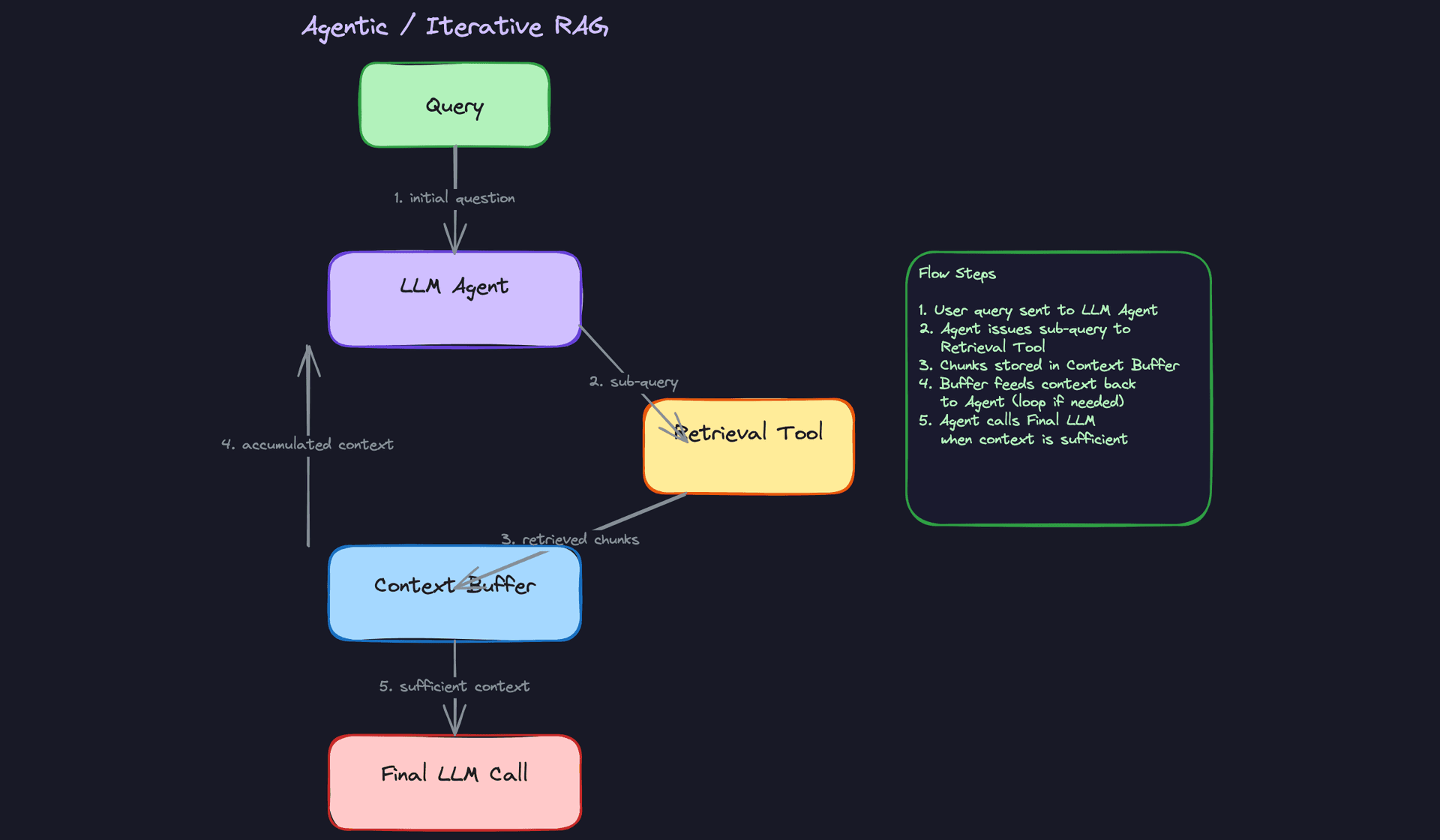
Agentic / Iterative RAG
Sometimes one retrieval round isn't enough. If a question requires synthesizing information across multiple documents, or if the answer to the first retrieval reveals a follow-up question, a single-shot RAG pipeline will fail. Agentic RAG lets the LLM decide: after seeing the retrieved context, it either generates a final answer or issues another retrieval query. This loops until the model judges the context sufficient.
Frameworks like LangChain and LlamaIndex implement this as a tool-calling loop. The LLM calls a retrieval tool, accumulates chunks in a context buffer, and decides when to stop. The power is real, especially for multi-hop reasoning. But latency becomes unpredictable because you can't bound the number of retrieval rounds. In an interview, mention this pattern when the problem involves complex, multi-step questions, and immediately follow it with how you'd add a max-iteration guard to prevent runaway loops.
Key insight: Agentic RAG is the right answer for complexity, but it's the wrong answer for latency-sensitive applications. If the interviewer mentions a customer-facing chatbot with a 2-second SLA, steer toward two-stage re-ranking instead.
Comparing the Patterns
| Pattern | Best For | Main Tradeoff | Complexity |
|---|---|---|---|
| Naive RAG | Prototypes, simple corpora | Poor precision on complex queries | Low |
| Hybrid Retrieval | Mixed corpora, exact + semantic needs | Requires two retrieval systems | Medium |
| HyDE | Short or vague queries | Extra LLM call adds latency | Medium |
| Two-Stage Re-ranking | High-precision requirements | Latency from re-ranker scoring | Medium-High |
| Agentic RAG | Multi-hop, complex reasoning | Unbounded latency, harder to debug | High |
For most interview problems, you'll default to hybrid retrieval with a re-ranker. It covers the widest range of real-world failure modes without the unpredictability of an agentic loop. Reach for HyDE when the interviewer specifies that queries are short and recall is suffering. Propose agentic RAG only when the use case explicitly involves multi-step reasoning, and pair it immediately with a discussion of how you'd constrain it.
What Trips People Up
Here's where candidates lose points — and it's almost always one of these.
The Mistake: Treating Chunking as a Detail
Most candidates say something like "I'd split the documents into chunks and embed them." The interviewer follows up: "How big are the chunks?" Silence. Or worse: "Maybe 512 tokens?"
Fixed-size chunking is the default, but it's also the worst option for retrieval quality. A 512-token window that cuts across a paragraph boundary can split a question from its answer, or separate a claim from the evidence that supports it. The retrieved chunk looks relevant by cosine similarity but is semantically incomplete. The LLM then hallucinates to fill the gap.
What you want to say instead: "I'd start with sentence-boundary or paragraph-level chunking to preserve semantic units. For structured documents like PDFs with headers, I'd chunk by section. I'd also experiment with overlapping windows so context at chunk edges isn't lost." Then mention that chunk size is a tunable parameter you'd validate against a retrieval eval set, not just pick once and forget.
Interview tip: Chunking strategy is one of the highest-signal topics in a RAG interview. Mentioning overlap, semantic boundaries, and document structure in the same breath signals you've actually built this, not just read about it.
The Mistake: Ignoring Embedding Model Consistency
This one is subtle, and candidates almost never bring it up unprompted. The failure mode sounds like: "We'd use OpenAI embeddings to index the documents, and then embed the query at search time." That's fine as far as it goes. But the interviewer asks: "What happens when you upgrade your embedding model?"
If you re-index only new documents with the updated model, your vector index now contains embeddings from two different models living in the same space. They're not comparable. Cosine similarity between a v1 embedding and a v2 embedding is meaningless. Retrieval silently degrades, and it's extremely hard to debug because the system still returns results.
The right answer: treat the embedding model as a versioned dependency. When you update it, you need a full re-index. In practice that means maintaining a versioned index (index-v1, index-v2), running both in parallel during the cutover, and validating retrieval quality before switching traffic. This is the same class of problem as training-serving skew in feature stores, and framing it that way will land well with an ML-focused interviewer.
The Mistake: Assuming More Context Is Always Better
"I'd retrieve the top-20 chunks to give the LLM as much information as possible." This sounds thorough. It's actually a problem.
LLMs don't process long contexts uniformly. There's a well-documented phenomenon called "lost in the middle": models tend to anchor on information at the beginning and end of the context window, and systematically underweight content in the middle. Stuffing 20 chunks into a prompt doesn't improve answer quality; it often degrades it, while also blowing up your token costs and latency.
Common mistake: Candidates treat the context window like a bucket you should fill. Interviewers hear "this person hasn't thought about what the LLM actually does with the context."
The better framing: retrieval precision matters more than recall at the prompt-assembly stage. Fetch a broader candidate set (top-50), re-rank it, and inject only the top-3 to top-5 most relevant chunks. Put the most important chunk first. If the question genuinely requires more context than that, you have a retrieval quality problem, not a context size problem.
The Mistake: Describing the System Without Any Evaluation Story
A candidate can walk through the entire RAG pipeline, name-drop Pinecone and Cohere Rerank, and still get a skeptical look from the interviewer. The question that exposes the gap: "How do you know if retrieval is actually working?"
The weak answer: "We'd look at user feedback" or "We'd monitor answer quality." These aren't wrong, but they're downstream signals that arrive too late and are too noisy to debug with.
What you should be able to say: you'd build an offline eval set of query-document pairs, either human-labeled or mined from click logs, and track recall@k (are the relevant documents in the top-k results?), MRR (where does the first relevant result appear?), and NDCG if you have graded relevance. You'd run this eval every time you change chunking strategy, swap embedding models, or tune retrieval parameters. That eval set is what lets you make changes confidently instead of guessing.
Mentioning that you'd also track answer faithfulness (does the generated answer contradict or hallucinate beyond the retrieved context?) shows you understand that retrieval quality and generation quality are separate failure modes that need separate measurement.
How to Talk About This in Your Interview
When to Bring It Up
RAG isn't always the right answer, so you want to reach for it at the right moment. The clearest signal is when the interviewer mentions that the system needs to answer questions grounded in private, proprietary, or frequently-updated data. "Our docs change weekly" or "users need answers from internal knowledge bases" are both green lights.
You should also bring it up when the interviewer asks how you'd avoid hallucinations in an LLM-based product. That's a direct invitation. Same goes for any mention of "knowledge cutoff" problems or "the model doesn't know about our product catalog."
If the conversation drifts toward fine-tuning as the only option for grounding a model, that's your cue to introduce RAG as the alternative, and then walk through when you'd use each.
Sample Dialogue
Interviewer: "Let's say you've built a basic RAG system and it's in production, but users are complaining the answers feel off. Retrieval seems to be returning irrelevant chunks. How do you even start debugging that?"
You: "I'd work through it in layers. First, I'd check whether the embedding model is actually a good fit for the domain. A general-purpose model like text-embedding-ada-002 might not capture the vocabulary well if you're dealing with, say, legal documents or medical records. I'd look at nearest-neighbor outputs for a handful of known queries and see if the results make intuitive sense."
Interviewer: "Okay, but assume the embeddings look reasonable. What else?"
You: "Then I'd look at chunking. Fixed-size chunking is the most common culprit. If you're splitting every 512 tokens regardless of sentence or paragraph boundaries, you end up with chunks that are semantically incomplete. A chunk that starts mid-sentence doesn't retrieve well and confuses the LLM. I'd switch to semantic chunking and re-index."
Interviewer: "And if chunking looks fine too?"
You: "At that point I'd look at the query side. Short or ambiguous queries often don't embed into a useful vector. HyDE helps here. You have the LLM generate a hypothetical answer first, embed that instead of the raw query, and retrieval quality usually jumps. If precision is still low after that, I'd add a cross-encoder re-ranker as a second stage. It's slower, but it scores each candidate against the query jointly rather than independently, which catches a lot of false positives the ANN search lets through."
Interviewer: "How do you know any of this is actually working better?"
You: "You need an offline eval set. A few hundred query-document pairs labeled by humans, and you track recall@k and MRR before and after each change. Without that, you're just guessing."
Follow-Up Questions to Expect
"Why not just fine-tune the model on your documents instead?" RAG handles knowledge (what the model knows), fine-tuning handles behavior (how it responds). Use RAG when documents change frequently or are too large to bake into weights; use fine-tuning when you need to adapt tone, format, or task style. In production, most serious systems use both.
"What's your latency budget look like for a RAG call?" Name the three hops: embedding inference is roughly 10ms, ANN search around 20ms, and LLM generation is the dominant cost at 500ms to 2 seconds depending on output length. The LLM is almost always the bottleneck, so you'd optimize there first, either with a smaller model, streaming, or caching common queries.
"How do you keep the index fresh when documents update?" You need a document ingestion pipeline that detects changes, re-chunks and re-embeds the affected documents, and upserts them into the vector store. The tricky part is embedding model versioning. If you ever swap embedding models, you need a full re-index, not a partial one, or you'll have inconsistent vector spaces in the same index.
"How would you monitor this in production?" Three things: retrieval quality (recall@k on your labeled eval set, run nightly), answer faithfulness (does the generated answer contradict or hallucinate beyond the retrieved context, which you can check with an LLM-as-judge setup), and per-stage latency so you know which hop is degrading.
What Separates Good from Great
- A mid-level candidate describes the query-time flow well but stops there. A senior candidate also describes the offline indexing pipeline, chunk versioning, and what happens when the embedding model gets updated. That's the difference between someone who's read the LangChain docs and someone who's run this in production.
- Mid-level answers treat retrieval as a black box that either works or doesn't. Senior answers treat it as a measurable system with an eval harness, labeled data, and metrics you can track over time.
- When the "RAG vs fine-tuning" question comes up, mid-level candidates pick one and defend it. Senior candidates immediately frame it as a spectrum and explain that the two solve different problems, then describe how they'd combine them.
Key takeaway: The candidates who stand out don't just describe how RAG works at query time; they talk about the full system, including the indexing pipeline, embedding model lifecycle, retrieval evaluation, and monitoring, because that's where the real engineering lives.
